自然语言处理(NLP)领域日新月异,大型语言模型(LLMs)的快速发展为我们带来了前所未有的机遇与挑战。其中,模型评估对人类标注数据的依赖是一个瓶颈,高昂的成本和耗时的数据收集工作限制了模型的有效评估和持续改进。 Downcodes小编将为大家介绍Meta FAIR研究人员提出的全新解决方案——“自学评估器”,它为解决这一难题提供了新的思路。
在当今时代,自然语言处理(NLP)领域发展迅速,大型语言模型(LLMs)能够高精度地执行复杂的语言相关任务,为人机交互带来了更多可能。然而,NLP 中存在一个显着问题,那就是模型评估对人类注释的依赖。
人类生成的数据对于模型的训练和验证至关重要,但收集这些数据既昂贵又耗时。而且,随着模型不断改进,先前收集的注释可能需要更新,其在评估新模型时的效用降低,这就导致需要持续获取新数据,给有效模型评估的规模化和可持续性带来了挑战。
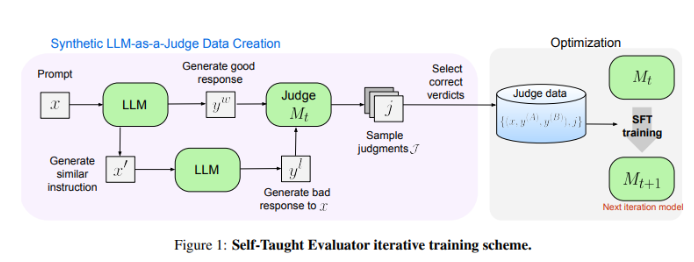
Meta FAIR 的研究人员带来了全新的解决方案——“Self-Taught Evaluator”(自学评估器)。这一方法无需人类注释,而是利用合成生成的数据进行训练。首先通过种子模型生成对比的合成偏好对,然后模型对这些对进行评估并迭代改进,利用自己的判断来提升后续迭代中的性能,大大降低了对人类生成注释的依赖。
研究人员使用Llama-3-70B-Instruct 模型对“自学评估器”的性能进行了测试。该方法将模型在RewardBench 基准上的准确性从75.4提高到88.7,达到甚至超越了使用人类注释训练的模型性能。经过多次迭代,最终模型在单次推理中达到88.3的准确率,多数投票下达到88.7,展现出其强大的稳定性和可靠性。
“自学评估器”为NLP 模型评估提供了可扩展且高效的解决方案,利用合成数据和迭代自我改进,应对了依赖人类注释的挑战,推动了语言模型的发展。
论文地址:https://arxiv.org/abs/2408.02666
Meta FAIR 的“自学评估器”为NLP 模型评估带来了革命性的变革,其高效、可扩展的特性将有力推动未来语言模型的持续进步。 这项研究成果不仅降低了对人类标注数据的依赖,更重要的是为构建更强大、更可靠的NLP 模型铺平了道路。 期待未来更多类似的创新成果问世!