人工智能图像生成领域日新月异,继Midjourney更新后,开源模型FLUX.1强势来袭,其性能据称超越了DALL·E3、Midjourney V6等闭源模型,以及SD3系列开源模型,引发业界广泛关注。Downcodes小编将带您深入了解这款由扩散模型领域权威专家Robin Rombach打造的全新力作,以及它背后的技术创新和未来展望。
在人工智能领域,每一天都可能发生颠覆性的变革。就在Midjourney刚刚进行大更新的第二天,开源图像生成领域就迎来了一匹令人瞩目的黑马——FLUX.1。这个突如其来的新玩家不仅在性能上声称大幅超越了DALL·E3、Midjourney V6等闭源模型,还将开源的SD3系列全线秒杀,瞬间引爆了AI圈。
让我们先来认识一下FLUX.1的幕后主脑。它的创始人Robin Rombach可不是什么无名之辈,而是扩散模型领域的权威专家。他的代表作包括VQGAN、Taming Transformers和Latent Diffusion,曾担任Stability AI的首席科学家,领导了全球知名的Stable Diffusion系列项目。可以说,Robin Rombach在AI图像生成领域可谓是老司机中的老司机。
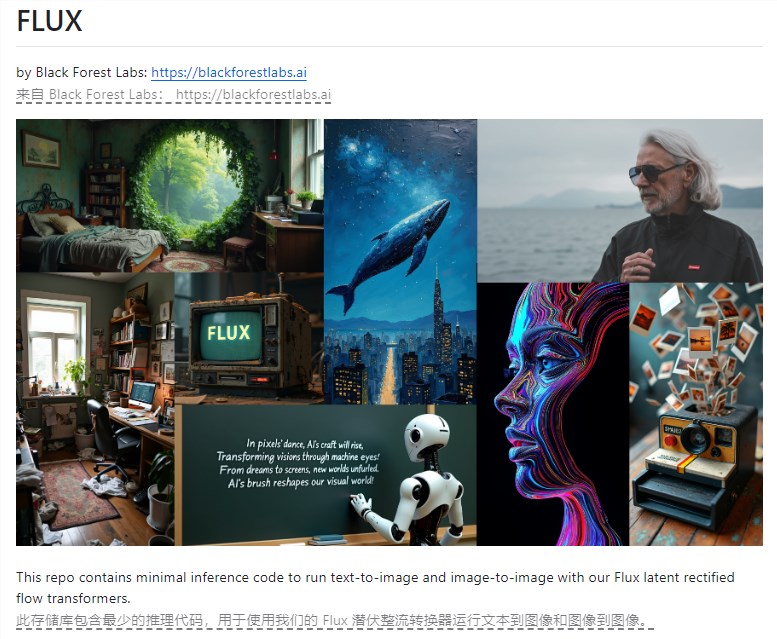
今年3月,由于Stability AI内部出现动荡,Robin选择离开。经过四个月的沉淀,他带着新的开源大模型平台FLUX.1重磅回归。更令人惊讶的是,FLUX.1一亮相就获得了由著名风投机构Andreessen Horowitz领投的3200万美元种子轮融资。这无疑为FLUX.1的未来发展注入了强心剂。
那么,FLUX.1到底有什么过人之处?首先,它基于Vision Transformer架构,采用了流程匹配训练方法,并使用旋转位置嵌入和并行注意层来提升模型性能和硬件利用效率。这120亿参数的模型推出了三个版本:
Pro版:通过API使用,性能最强劲。
Dev版:非商用的指导蒸馏模型,继承了Pro版的大部分性能。
Schnell版:可以商用的开源模型,性能也相当出色。
根据FLUX.1团队的测试数据,即便是开源的Schnell版本,在文本语义还原、图片质量、动作一致性、连贯性和多样性等方面,也超越了Midjourney v6.0、DALL·E3(HD)和SD3-Ultra等主流模型。特别是在文本嵌入图片方面,FLUX.1展现出了明显的优势。
这里,AIbase挑选了几张官方的生成效果展示,大家可以参考一下:
真实摄影图片
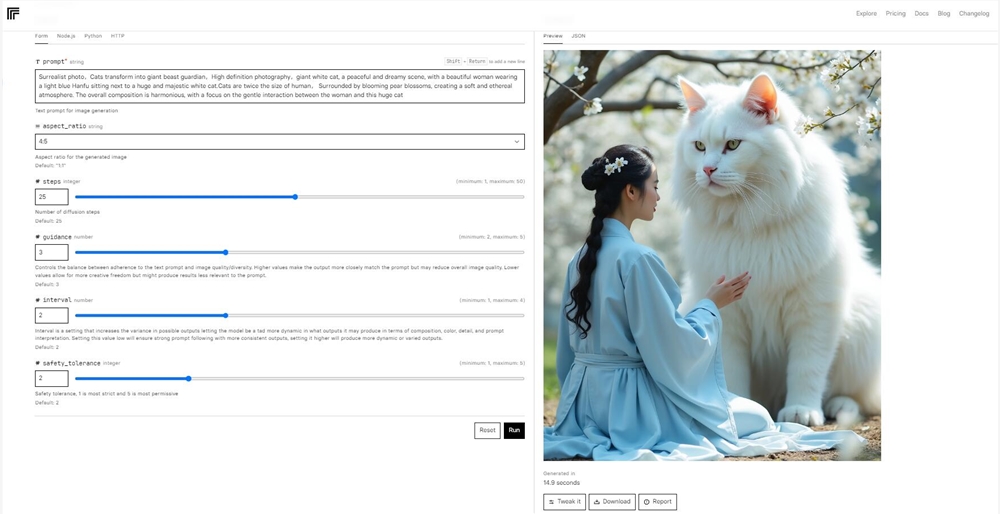
AIbase测试了一下之前的猫猫守护神,也完全没问题,FLUX.1对提示词的理解比较准确。
当然,FLUX.1的野心显然不止于此。团队表示,文生图只是一个开始,未来他们还计划推出文生视频模型,挑战Sora、Gen-3、Luma等一线产品。
对于开发者和AI爱好者来说,FLUX.1的出现无疑是一个重大利好。Schnell版本已经完全开源,并获得了Comfyui的支持。如果你有36G以上的显存,甚至可以运行t5的fp16版本。不过需要注意的是,t5xxl_fp16.safetensors或clip_l.safetensors以及VAE需要单独下载。
FLUX.1的横空出世,不仅为开源AI图像生成领域带来了新的希望,也为整个AI行业注入了新的活力。它的强大性能和开源特性,很可能会加速AI图像生成技术的普及和创新。对于普通用户来说,这意味着我们可能很快就能在家用电脑上运行媲美甚至超越Midjourney的AI图像生成模型。
项目地址:https://github.com/black-forest-labs/flux
试玩地址:https://replicate.com/black-forest-labs/flux-pro
Comfyui工作流:https://comfyanonymous.github.io/ComfyUI_examples/flux/
总而言之,FLUX.1的出现标志着开源AI图像生成领域进入了一个新的阶段,其强大的性能和开源特性将极大地推动AI图像生成技术的普及和发展。我们期待FLUX.1在未来带来更多惊喜!