Meta AI的最新项目Llama3引发广泛关注,Downcodes小编将带您深入了解其核心技术和未来发展方向。Meta AI研究员Thomas Scialom近日接受采访,分享了Llama3的研发细节,并对大型语言模型训练中存在的问题提出了独到的见解。他特别强调了合成数据在Llama3训练中的重要作用,以及如何有效利用人类反馈来提升模型性能。本文将详细解读Llama3的训练方法、应用领域以及未来的发展规划,为读者呈现一个全面而深入的视角。
Meta AI的研究员Thomas Scialom最近在一次采访中分享了一些关于他们最新项目Llama3的见解。他直言不讳地指出,网络上的大量文本质量参差不齐,他认为在这些数据上进行训练是一种资源浪费。因此,Llama3的训练过程中并没有依赖任何人类编写的答案,而是完全基于Llama2生成的合成数据。
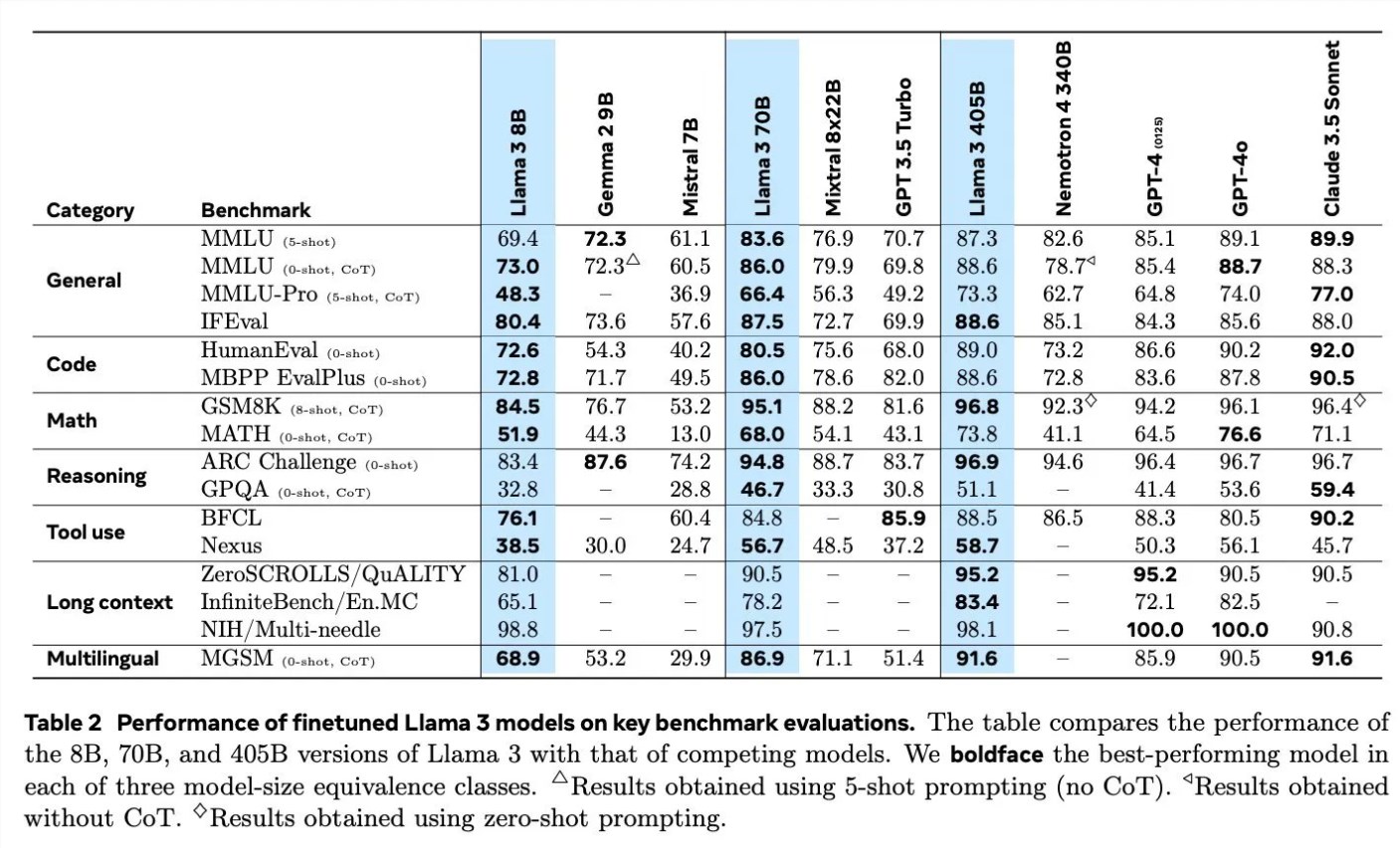
在讨论Llama3的训练细节时,Scialom详细介绍了合成数据在不同领域的应用。例如,在代码生成方面,他们采用了三种不同的方法来生成合成数据,包括代码执行的反馈、编程语言的翻译以及文档的反向翻译。在数学推理方面,他们借鉴了“让我们逐步验证”的研究方法来进行数据生成。此外,Llama3还通过90%的多语言令牌继续预训练,以收集高质量的人类注释,这在多语言处理上显得尤为重要。
长文本处理也是Llama3的一个重点,他们依赖合成数据来处理长文本的问答、长文档摘要和代码库推理。工具使用方面,Llama3在Brave搜索、Wolfram Alpha和Python解释器上进行了训练,以实现单次、嵌套、并行和多轮函数调用。
Scialom还提到了强化学习与人类反馈(RLHF)在Llama3训练中的重要性。他们广泛利用人类偏好数据来训练模型,并强调了人类在做出选择(比如在两首诗中选择更喜欢的一首)方面的能力,而不是从零开始创作。
Meta已经在6月份开始了Llama4的训练,Scialom透露,Llama4的一个主要焦点将是围绕智能体展开。此外,他还提到了多模态版本的Llama,这个版本将拥有更多的参数,并计划在不久的将来发布。
Scialom的访谈揭示了Meta AI在人工智能领域的最新进展和未来的发展方向,特别是在如何利用合成数据和人类反馈来提升模型性能方面。
通过Scialom的访谈,我们了解到Llama3在数据利用和模型训练上的创新之处,以及Meta AI在大型语言模型领域的持续探索。Llama3的成功经验为未来人工智能模型的研发提供了宝贵的参考,也预示着人工智能技术将朝着更精准、更高效的方向发展。 Downcodes小编期待Llama4及多模态Llama的发布,并持续关注Meta AI在人工智能领域的突破性进展。