Meta公司重磅发布!开源其最新大语言模型Llama 3.1 405B,参数量高达1280亿,在多项任务中表现可与GPT-4媲美。历经一年精心筹备,从项目规划到最终审核,Llama 3系列模型终于与公众见面。此次开源不仅包含模型本身,还包括其优化的预训练数据处理、训练后数据质量保证以及高效的量化技术,以降低计算需求,方便开发者使用。Downcodes小编将为您详细解读Llama 3.1 405B的各项改进和亮点。
昨晚,Meta公司宣布开源其最新大语言模型Llama3.1 405B。这一重磅消息标志着经过一年的精心筹备,从项目规划到最终审核,Llama3系列模型终于与公众见面。
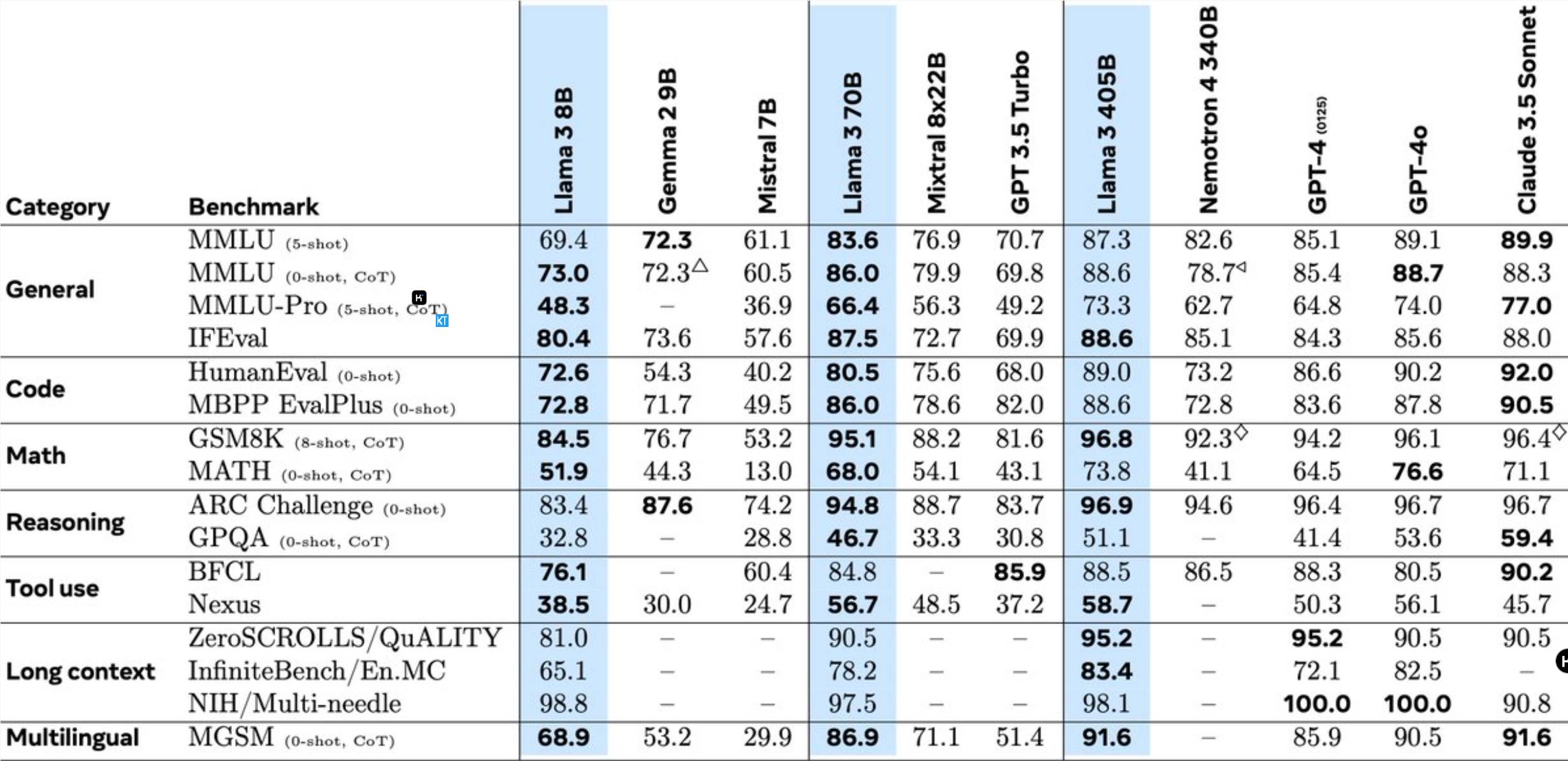
Llama3.1405B是一个具有1280亿参数的多语言工具使用模型。该模型在8K上下文长度预训练后,进一步通过128K上下文长度持续训练而成。根据Meta的说法,这个模型在多项任务中的表现可与业界领先的GPT-4相媲美。
相较于先前的Llama模型,Meta在多个方面进行了优化:
405B模型的预训练是一项巨大挑战,涉及15.6万亿个标记和3.8x10^25次浮点运算。为此,Meta优化了整个训练架构,并调用了超过16,000块H100GPU。
为支持405B模型的大规模生产推理,Meta将其从16位(BF16)量化至8位(FP8),显著降低了计算需求,使单个服务器节点也能运行该模型。
此外,Meta利用405B模型提升了70B和8B模型的训练后质量。在训练后阶段,团队通过多轮对齐过程完善了聊天模型,包括监督式微调(SFT)、拒绝采样和直接偏好优化。值得注意的是,大部分SFT样本都是使用合成数据生成的。
Llama3还整合了图像、视频和语音功能,采用组合方法使模型能够识别图像和视频,并支持语音交互。不过,这些功能仍在开发中,尚未正式发布。
Meta还更新了许可协议,允许开发者使用Llama模型的输出来改进其他模型。
Meta的研究人员表示:能与业内顶尖人才一起在AI前沿工作,并公开透明地发布研究成果,是无比令人振奋的。我们期待看到开源模型带来的创新,以及未来Llama系列模型的潜力!
这一开源举措无疑将为AI领域带来新的机遇和挑战,推动大语言模型技术的进一步发展。
Llama 3.1 405B的开源,将极大推动大语言模型技术的进步,为AI领域带来更多可能性。期待开发者们基于此模型创造出更多令人惊艳的应用!