大型语言模型的效率提升一直是人工智能领域的研究热点。近日,来自Aleph Alpha、达姆施塔特工业大学等机构的研究团队研发出了一种名为T-FREE的新方法,显着提高了大型语言模型的运行效率。该方法通过利用字符三元组进行稀疏激活,减少了嵌入层参数数量,并有效地对单词间的形态相似性进行建模,在保证模型性能的同时,大幅降低了计算资源消耗。这项突破性的技术为大型语言模型的应用带来了新的可能性。
研究团队最近带来了一个令人兴奋的新方法,叫做T-FREE,让大型语言模型的运作效率直线上升。来自Aleph Alpha、达姆施塔特工业大学、hessian.AI 和德国人工智能研究中心(DFKI)的科学家们联合推出了这个令人惊叹的技术,它的全名是“无需标记器的稀疏表示,可实现内存高效嵌入”。
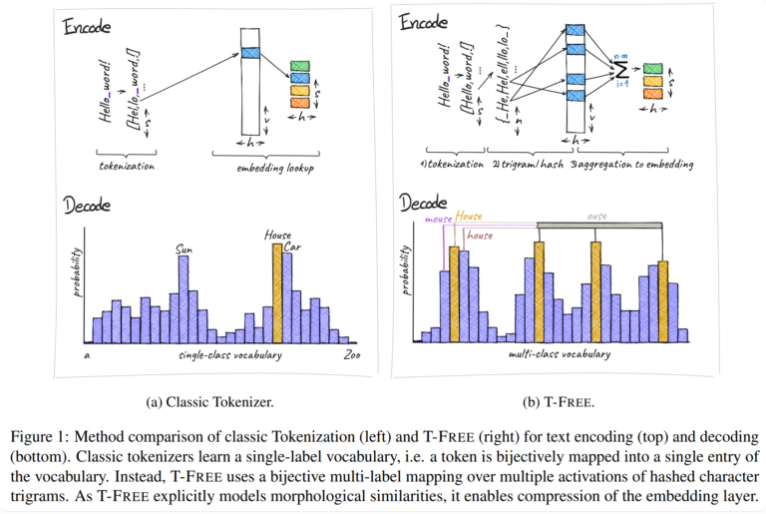
传统上,我们使用标记器将文本转化为计算机能理解的数字形式,但T-FREE 选择了一条不同的路。它利用字符三元组,也就是我们称之为“三元组” 的东西,通过稀疏激活的方式直接将单词嵌入模型中。这一创新举措的结果是,嵌入层的参数数量减少了惊人的85% 以上,同时在处理文本分类和问答等任务时,模型的性能丝毫未受影响。
T-FREE 的另一大亮点在于它非常聪明地对单词间的形态相似性进行了建模。就像我们在日常生活中经常碰到的“house”、“houses” 和“domestic” 这些词,T-FREE 能更有效地将这些相似的词在模型中表示出来。研究人员认为,相似的词在嵌入时应该彼此靠得更近,从而实现更高的压缩率。因此,T-FREE 不仅减小了嵌入层的体积,还将文本的平均编码长度减少了56%。
更值得一提的是,T-FREE 在不同语言之间的迁移学习方面表现得尤为出色。在一项实验中,研究人员使用一个拥有30亿参数的模型,先用英语进行训练,再用德语进行训练,结果发现T-FREE 的适应性远超传统的基于标记器的方法。
不过,研究人员也对目前的成果保持谦虚。他们承认,至今为止的实验仅限于多达30亿参数的模型,未来还计划在更大的模型和更庞大的数据集上进行进一步评估。
T-FREE 方法的出现为大型语言模型的效率提升提供了新的思路,其在降低计算成本和提升模型性能方面的优势值得关注。未来的研究方向将集中在更大规模的模型和数据集上的验证,以进一步拓展T-FREE 的应用范围,并推动大型语言模型技术的持续发展。相信在不久的将来,T-FREE 将在更多领域发挥其重要作用。