昆仑万维近日宣布其研发的两款奖励模型Skywork-Reward-Gemma-2-27B和Skywork-Reward-Llama-3.1-8B在RewardBench上取得优异成绩,其中27B模型更是荣登榜首。这标志着昆仑万维在人工智能领域,特别是奖励模型研发方面取得了重大突破,为大语言模型训练提供了新的技术支持。奖励模型在强化学习中至关重要,它能够引导模型学习,生成更符合人类偏好的内容。昆仑万维的模型在数据选择和模型训练上具有独特的优势,这使得其在对话、安全性等方面表现出色,尤其是在处理困难样本时展现出强大的能力。
昆仑万维科技股份有限公司近日宣布,公司研发的两款全新奖励模型Skywork-Reward-Gemma-2-27B和Skywork-Reward-Llama-3.1-8B在国际权威的奖励模型评估基准RewardBench上表现卓越,其中Skywork-Reward-Gemma-2-27B模型更是荣获榜首,得到了RewardBench官方的高度认可。
奖励模型在强化学习中占据核心地位,对智能体在不同状态下的表现进行评估,并提供奖励信号指导智能体的学习过程,使其能够在特定环境下做出最优选择。在大语言模型的训练中,奖励模型的作用尤为关键,有助于模型更准确地理解和生成符合人类偏好的内容。
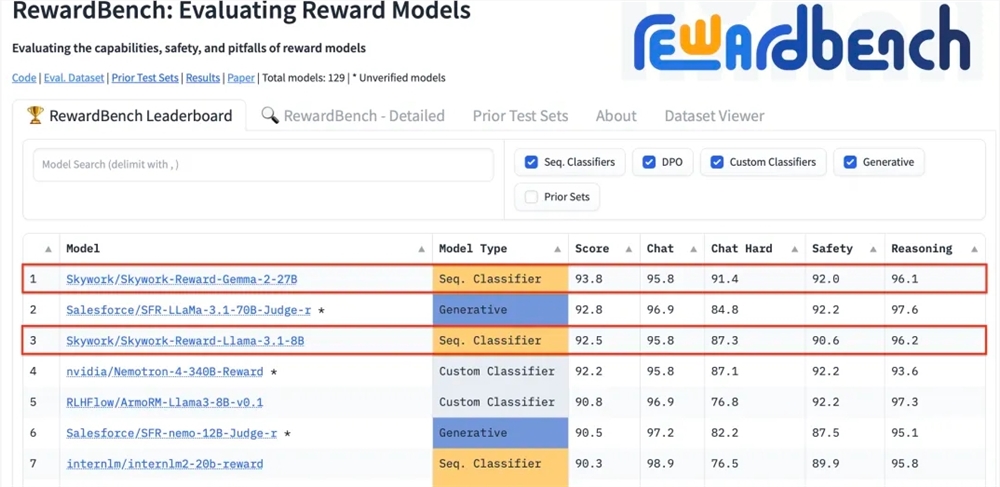
RewardBench是一个专门评估大语言模型中奖励模型有效性的基准测试榜单,通过多项任务对模型进行综合评估,包括对话、推理和安全性等领域。该榜单的测试数据集由提示词、被选响应和被拒绝响应组成的三元组构成,用以测试奖励模型是否能够在给定提示词的情况下,将被选响应正确地排在被拒绝响应之前。
昆仑万维的Skywork-Reward模型通过精心挑选的偏序数据集和相对较小的基座模型进行开发,与现有奖励模型相比,其偏序数据仅来源于网络公开数据,并通过特定筛选策略获得高质量的偏好数据集。这些数据涵盖了广泛的主题,包括安全性、数学与代码等,并经过人工验证,确保数据的客观性和奖励差距的显著性。
经过测试,昆仑万维的奖励模型在对话、安全性等领域展现了出色的表现,尤其在面对困难样本时,只有Skywork-Reward-Gemma-2-27B模型给出了正确的预测。这一成就标志着昆仑万维在全球AI领域的技术实力和创新能力,同时也为AI技术的发展和应用提供了新的可能性。
27B模型地址:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
8B模型地址:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
昆仑万维在RewardBench上的优异表现,展现了其在人工智能领域的领先技术和创新能力,也为大语言模型的未来发展提供了新的方向和可能性,期待其未来带来更多突破性成果。