Nous Research 推出革命性AI 训练优化器DisTrO,打破了大型AI 模型训练仅限于大型公司巨头的局面。 DisTrO 能够显着减少多GPU之间的数据传输量,即使在普通网络环境下也能高效训练AI模型,这将极大地降低AI模型训练的门槛,让更多个人和机构能够参与到AI技术的研究和开发中来。这项创新技术有望彻底改变AI领域的研发模式,促进AI技术的普及和发展。
最近,Nous Research 的研究团队给科技圈带来了一个令人振奋的消息,他们推出了一种名为DisTrO(分布式互联网训练)的新优化器。这项技术的诞生,意味着强大的AI 模型不仅仅是大公司的专利,普通人也有机会在家里用自己的电脑进行高效训练。
DisTrO 的神奇之处在于,它能够显着减少在训练AI 模型时,多个图形处理单元(GPU)之间需要传输的信息量。通过这一创新,强大的AI 模型可以在普通的网络条件下进行训练,甚至让全球各地的个人或机构联手合作,共同开发AI 技术。
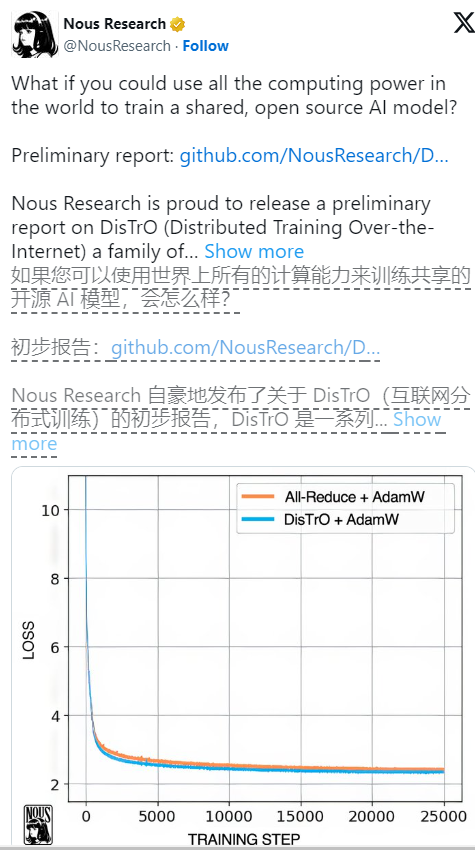
根据Nous Research 的技术论文,DisTrO 的效率提升惊人,使用它的训练效率比一种常见的算法——All-Reduce 提高了857倍,同时每一步训练所需传输的信息量也从74.4GB 降低到了86.8MB。这样的提升,不仅让训练变得更快、更便宜,还意味着更多的人有机会参与到这个领域中来。
Nous Research 在其社交平台上表示,通过DisTrO,研究人员和机构不再需要依赖某一家公司来管理和控制训练过程,这为他们提供了更多的自由去进行创新和实验。这种开放的竞争环境,有助于推动技术进步,最终惠及整个社会。
在AI 训练中,硬件的需求常常令人望而却步。尤其是高性能的Nvidia GPU 在这个时代变得愈发稀缺且昂贵,只有一些资金雄厚的公司才能承担得起这种训练的重负。然而,Nous Research 的理念则完全相反,他们致力于以较低的成本,向公众开放AI 模型的训练,努力让更多人能够参与。
DisTrO 的工作原理是,通过降低GPU 之间的全梯度同步需求,将通信开销减少了四到五个数量级。这一创新,使得AI 模型能够在速度较慢的互联网连接下进行训练,如今许多家庭能够轻松访问的100Mbps 下载和10Mbps 上传的速度都足够用了。
在对Meta 的Llama2大型语言模型进行的初步测试中,DisTrO 显示出了与传统方法相当的训练效果,同时却大幅降低了所需的通信量。研究者们还表示,虽然目前只在较小的模型上进行了测试,但他们初步猜测,随着模型规模的增大,通信需求的降低可能会更加显着,甚至达到1000到3000倍。
值得注意的是,尽管DisTrO 让训练变得更加灵活,它仍然依赖于GPU 的支持,只不过现在这些GPU 不需要聚集在同一个地方,而是可以分散在世界各地,通过普通互联网进行协作。我们看到,DisTrO 在使用32个H100GPU 进行严格测试时,能够与传统的AdamW+All-Reduce 方法在收敛速度上相匹配,但却大幅度降低了通信需求。
DisTrO 不仅适用于大型语言模型,也有可能用于训练图像生成模型等其他类型的AI,未来的应用前景令人期待。此外,通过提高训练效率,DisTrO 还可能减少AI 训练对环境的影响,因为它更优化了现有基础设施的使用,降低了对大型数据中心的需求。
通过DisTrO,Nous Research 不仅推动了AI 训练的技术进步,还促进了一个更加开放和灵活的研究生态系统,这为未来的AI 发展开启了无限可能。
参考资料:https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/
DisTrO 的出现预示着AI 训练的民主化进程,降低了参与门槛,推动了AI 技术的快速发展和广泛应用,为AI 领域带来新的活力和无限可能。未来,期待DisTrO 能为AI 发展带来更多惊喜。