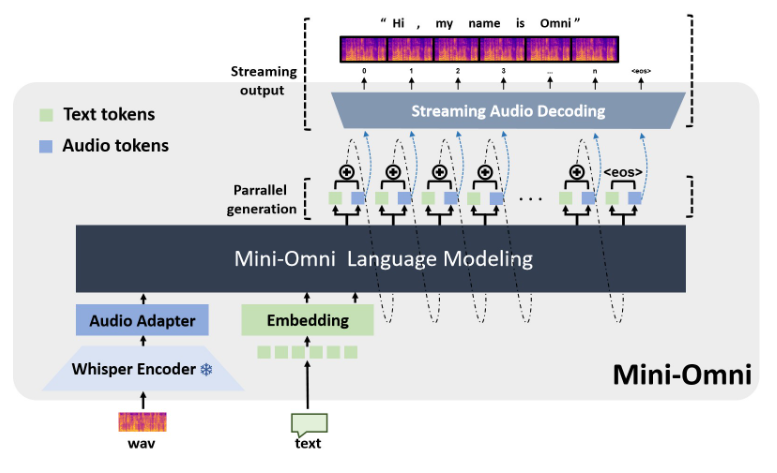
Mini-Omni,一个开源的多模态大型语言模型,正在革新语音交互技术。它集成了先进技术,实现实时语音输入输出,并具备边思考边说话的能力,带来更自然流畅的人机交互体验。Mini-Omni的核心优势在于其端到端的实时语音处理能力,无需额外配置ASR或TTS模型,即可享受流畅对话。它支持多种模态输入并灵活转换,适应各种复杂场景,满足多样化需求。
在人工智能快速发展的今天,一款名为Mini-Omni的开源多模态大型语言模型正在引领语音交互技术的革新。这个由多个先进技术集成而成的AI系统,不仅能够实现实时的语音输入和输出,还具备边思考边说话的独特能力,为用户带来前所未有的自然交互体验。
Mini-Omni的核心优势在于其端到端的实时语音处理能力。用户无需额外配置自动语音识别(ASR)或文本转语音(TTS)模型,就能享受到流畅的语音对话。这种无缝衔接的设计大大提升了用户体验,使人机交互更加自然和直观。
除了语音功能,Mini-Omni还支持文本等多种模态的输入,并能在不同模态之间灵活转换。这种多模态处理能力使得模型可以适应各种复杂的交互场景,满足用户多样化的需求。
特别值得一提的是Mini-Omni的Any Model Can Talk功能。这项创新使得其他AI模型能够轻松集成Mini-Omni的实时语音能力,极大地扩展了AI应用的可能性。这不仅为开发者提供了更多选择,也为AI技术的跨领域应用铺平了道路。
在性能方面,Mini-Omni展现出了全面的实力。它不仅在语音识别(ASR)和语音生成(TTS)等传统语音任务中表现出色,在TextQA、SpeechQA等需要复杂推理能力的多模态任务中也显示出强大的潜力。这种全面的能力使得Mini-Omni能够应对各种复杂的交互场景,从简单的语音指令到需要深度思考的问答任务,都能游刃有余。
Mini-Omni的技术实现融合了多个先进的AI模型和技术。它以Qwen2作为大型语言模型的基础,利用litGPT进行训练和推理,采用whisper进行音频编码,snac负责音频解码。这种多技术融合的方法不仅提高了模型的整体性能,也增强了其在不同场景下的适应能力。
对于开发者和研究人员来说,Mini-Omni提供了便捷的使用方式。通过简单的安装步骤,用户就能在本地环境中启动Mini-Omni,并通过Streamlit和Gradio等工具进行交互式演示。这种开放和易用的特性,为AI技术的普及和创新应用提供了有力支持。
项目地址:https://github.com/gpt-omni/mini-omni
Mini-Omni凭借其强大的功能、便捷的使用方式以及开放的开源特性,为AI语音交互领域带来了新的可能性,值得开发者和研究人员关注和探索。其未来发展也值得期待。