Mamba团队的研究取得了突破性进展,他们成功地将大型Transformer模型Llama“蒸馏”成更高效的Mamba模型。该研究巧妙地结合了渐进式蒸馏、监督微调和定向偏好优化等技术,并针对Mamba模型的独特结构,设计了一种新型的推理解码算法,显着提升了模型的推理速度,在保证性能不损失的前提下实现了效率的大幅提升。这项研究不仅降低了大型模型训练的成本,也为未来模型优化提供了新的思路,具有重要的学术意义和应用价值。
最近,Mamba 团队的研究令人瞩目:来自康奈尔和普林斯顿等高校的研究者们成功将Llama 这一大型Transformer 模型“蒸馏” 成了Mamba,并设计了一种新型的推理解码算法,显着提高了模型的推理速度。
研究人员的目标是让Llama 变成Mamba。为什么这么做呢?因为从零开始训练一个大型模型代价高昂,而Mamba 自问世以来受到了广泛关注,但实际上很少有团队自己训练大规模的Mamba 模型。虽然市面上有一些名声在外的变种,比如AI21的Jamba 和NVIDIA 的Hybrid Mamba2,但众多成功的Transformer 模型中蕴藏了丰富的知识。如果我们能够锁住这些知识,同时将Transformer 微调为Mamba,那问题就迎刃而解了。
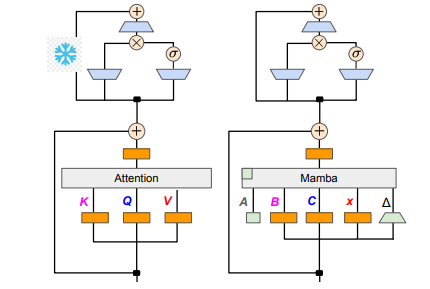
研究团队结合了渐进式蒸馏、监督微调和定向偏好优化等多种方法,成功达成了这个目标。值得注意的是,在保证性能不打折的前提下,速度也显得至关重要。 Mamba 在长序列推理中的优势非常明显,而Transformer 也有推理加速方案,比如推测解码。由于Mamba 的独特结构无法直接应用这些方案,研究者们特意设计了一种全新的算法,并结合硬件特性来实现基于Mamba 的推测解码。
最终,研究人员将Zephyr-7B 和Llama-38B 成功转换为线性RNN 模型,且性能与蒸馏前的标准模型相当。整个训练过程仅使用了20B 的token,结果与使用1.2T 个token 从头训练的Mamba7B 模型及3.5T 个token 训练的NVIDIA Hybrid Mamba2模型不相上下。
在技术细节方面,线性RNN 与线性注意力是相通的,因此研究者能够直接复用注意力机制中的投影矩阵,并通过参数初始化完成模型构建。此外,研究团队冻结了Transformer 中MLP 层的参数,逐步用线性RNN 层(即Mamba)替换掉注意力头,并对跨头共享键和值的分组查询注意力进行了处理。
在蒸馏过程中,采用了逐步替换注意力层的策略。监督微调包括两种主要方法:一种是基于word-level 的KL 散度,另一种是序列级知识蒸馏。针对用户偏好的调优阶段,团队利用了直接偏好优化(DPO)的方法,通过与老师模型的输出进行对比,确保模型在生成内容时能更好地符合用户的期望。
接下来,研究者们开始将Transformer 的推测解码应用到Mamba 模型中。推测解码可以简单理解为用一个小模型生成多个输出,然后使用大模型对这些输出进行验证。小模型运行迅速,可以快速生成多个输出向量,而大模型则负责评估这些输出的准确性,从而提升整体推理速度。
为了实现这一过程,研究者们设计了一套算法,每次使用小模型生成K 个草稿输出,随后大模型通过验证返回最终的输出和中间状态的缓存。这一方法在GPU 上得到了很好的效果,Mamba2.8B 实现了1.5倍的推理加速,且接受率达到了60%。尽管在不同架构的GPU 上效果有所差异,研究团队通过融合内核和调整实现方式进行进一步优化,最终达成了理想的加速效果。
在实验阶段,研究人员利用Zephyr-7B 和Llama-3Instruct8B 进行了三阶段的蒸馏训练,最终仅需在8卡80G A100上运行3到4天,便成功复现了研究成果。这项研究不仅展示了Mamba 与Llama 之间的转变之路,也为未来模型的推理速度和性能提升提供了新的思路。
论文地址:https://arxiv.org/pdf/2408.15237
这项研究为大型语言模型的效率提升提供了宝贵的经验和技术方案,其成果有望应用于更多领域,推动人工智能技术的进一步发展。论文地址的提供方便了读者更深入地了解研究细节。