北京智源人工智能研究院(BAAI)于2024年9月4日重磅推出FlagEval大模型角斗场,这是全球首个包含文生视频的模型对战评测服务。该服务面向公众开放,涵盖了国内外约40款大模型,支持语言问答、多模态图文理解、文生图、文生视频四大任务的自定义在线或离线评测,并创新性地引入了主观倾向阶梯评分体系,力求更精准地评估模型性能。FlagEval不仅提供简单理解、知识应用、代码能力、推理能力等多种预设问题的评测,还采用匿名机制,确保评测过程的公正性和客观性。用户可通过网页端或移动端参与评测,实时查看评分结果和角斗场榜单。
2024年9月4日,北京智源人工智能研究院(BAAI)宣布推出全球首个包含文生视频的模型对战评测服务——FlagEval大模型角斗场。
这一服务面向用户开放,覆盖了国内外约40款大模型,并支持语言问答、多模态图文理解、文生图、文生视频等四大任务的自定义在线或离线评测。FlagEval大模型角斗场的推出,不仅提供了简单理解、知识应用、代码能力、推理能力等多种预设问题的评测,还首次引入了主观倾向阶梯评分体系,以更精确地揭示模型性能差异。
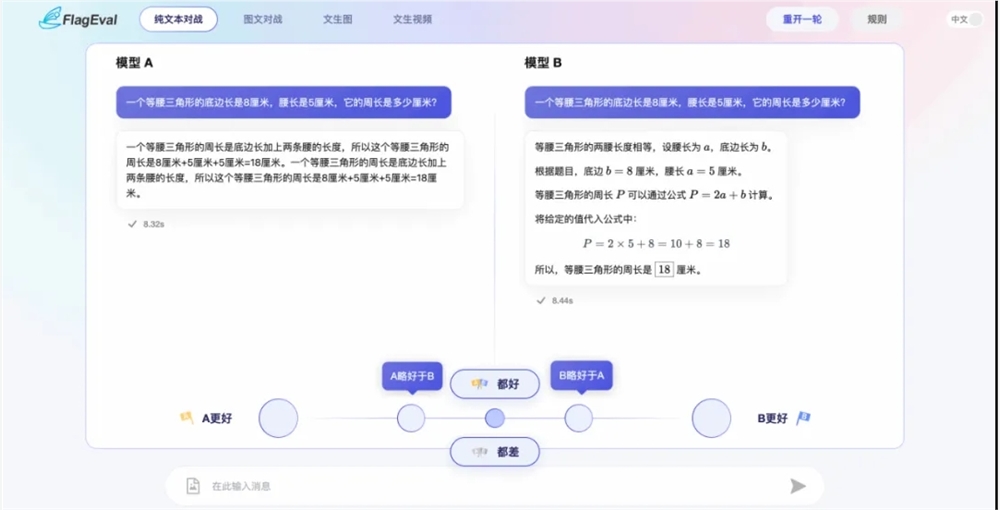
该服务采取匿名机制进行评测,确保评测过程的公正性。用户可以通过网页端或国内首个移动端访问入口参与评测,体验高效的模型对战评测。FlagEval大模型角斗场的评分结果将即时公示,形成角斗场榜单,展现各模型的对战能力。
智源研究院表示,将对模型对战评测的全链路数据进行开源,以促进大模型评测生态的发展。FlagEval大模型角斗场的推出,进一步拓展了智源在模型评测领域的技术布局和工具方法的研发,为人工智能领域的研究和应用提供了新的测试和评估工具。
体验地址:https://flageval.baai.ac.cn/#/home
智源研究院开源FlagEval大模型角斗场的数据,旨在推动大模型评测生态的健康发展,为人工智能领域的持续进步提供有力支撑。 欢迎访问体验地址,参与评测,共同推动AI技术发展!