在信息爆炸的时代,精准高效的信息筛选至关重要。推荐系统作为信息过载的解决方案,却常常面临推荐结果与用户喜好偏差的问题。来自香港大学团队研发的EasyRec,为这一难题提供了一种创新的解决方案。它是一款基于语言模型的推荐系统,即使在数据匮乏的情况下,也能准确预测用户偏好,提升推荐效率。
在信息泛滥的时代,推荐系统成为了我们筛选信息的重要助手。但是,你是否曾因为推荐内容不合口味而感到失望?或者在使用新应用时,推荐系统似乎总是无法精准把握你的需求?现在,EasyRec 的出现,或许能够解决这些难题。
EasyRec,由香港大学的团队开发,是一款基于语言模型的推荐系统。它的独特之处在于,即使在没有大量用户数据的情况下,也能通过分析文本信息来预测用户的喜好。
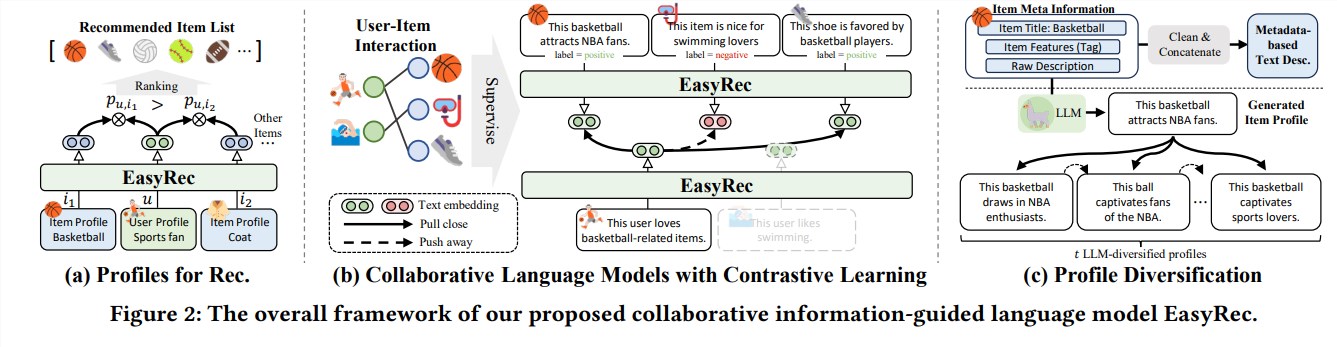
该系统的核心技术是文本行为对齐框架。这项技术通过分析用户的行为故事,比如浏览的商品和阅读的评价,结合其中的情感和细节,来预测用户的潜在喜好。
EasyRec 的智能之处在于它结合了对比学习和协同语言模型。系统不仅学习用户喜好的商品特征,也学习其他用户的数据,通过对比分析,找出最有可能吸引用户的商品。
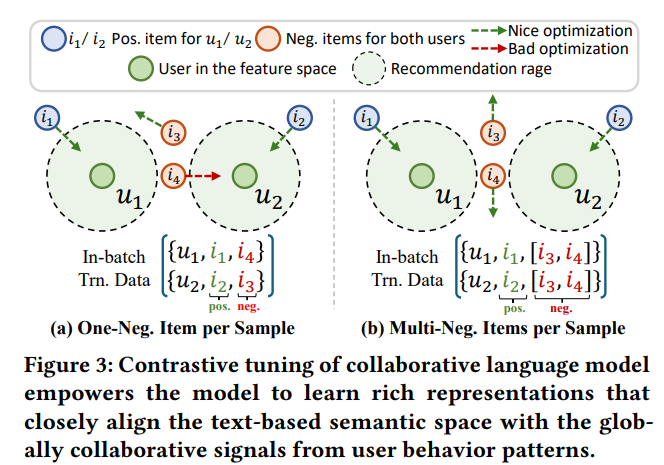
在多个真实世界数据集上的测试表明,EasyRec 在推荐准确性上超越了现有模型,特别是在处理新用户和新商品的零样本推荐场景中表现出色。
EasyRec 的另一个优势是它的即插即用特性,可以轻松集成到现有的推荐系统中。这使得无论是商业用户还是学术研究者,都能快速提升推荐系统的性能。
随着技术的不断进步,EasyRec 的潜力正在被进一步挖掘。它不仅能提升商业推荐系统的理解能力,还可能为学术研究带来新的突破。
论文地址:https://arxiv.org/pdf/2408.08821
EasyRec凭借其独特的文本行为对齐框架和对比学习机制,在零样本推荐场景下展现出优异的性能,为解决推荐系统面临的挑战提供了新的思路。其即插即用的特性也方便了广泛应用,值得期待其在未来商业和学术领域的进一步发展。