魔搭ModelScope社区开源了其国产开源Sora视频生成模型CogVideoX的升级版本——CogVideoX-5B,这是一个基于大规模DiT模型的文本到视频生成模型。相比之前的CogVideoX-2B,新模型在视频质量和视觉效果上有了显着提升。 CogVideoX-5B利用了3D因果变分自编码器(3D causal VAE)和专家Transformer技术,并采用3D-RoPE作为位置编码和3D全注意力机制进行时空联合建模,还使用了渐进式训练技术,能够生成更长、更高质量、更具运动特征的视频。
与之前的CogVideoX-2B相比,新模型在视频生成的质量和视觉效果上都有显着提升。
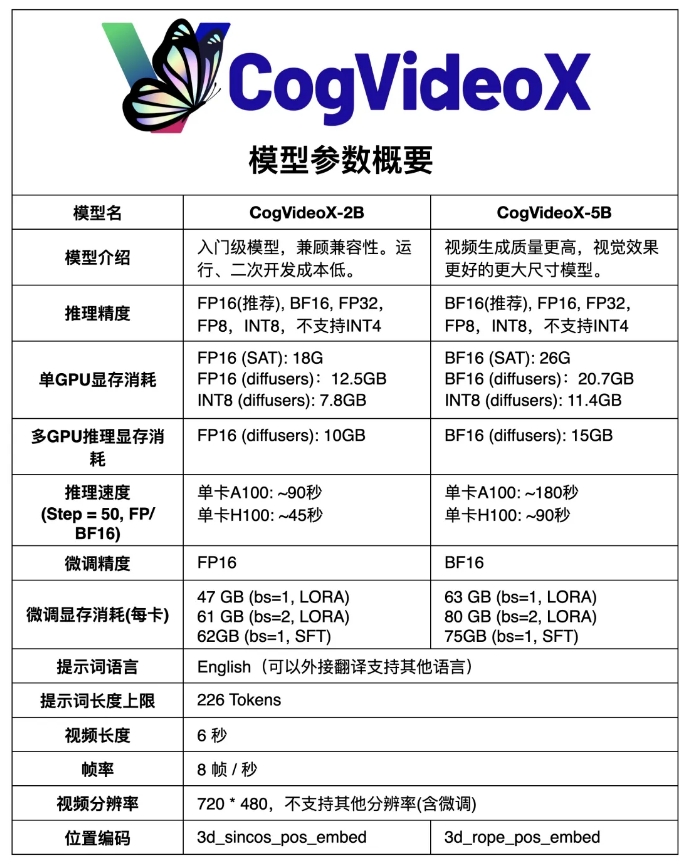
CogVideoX-5B是一个基于大规模DiT(diffusion transformer)模型,专为文本到视频生成任务设计。模型采用了3D因果变分自编码器(3D causal VAE)和专家Transformer技术,通过结合文本和视频嵌入,使用3D-RoPE作为位置编码,并利用3D全注意力机制进行时空联合建模。
此外,模型还采用了渐进式训练技术,能够生成具有显着运动特征、连贯且长时间的高质量视频。
模型链接:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
CogVideoX-5B的开源,为国内AI视频生成领域带来了新的技术突破和发展机遇,也为研究人员和开发者提供了强大的工具和资源。相信未来会有更多基于CogVideoX-5B的创新应用出现,推动AI视频生成技术的不断进步。该模型的便捷访问也降低了研究和应用的门槛,促进技术更广泛地传播和应用。