UCSC-VLAA团队发布了庞大的多模态医学数据集MedTrinity-25M,包含2500万张医学影像及详细注释,这标志着医学领域数据资源的一次重大飞跃。该数据集的多粒度注释使得研究人员能够更深入地理解和应用医疗数据,并为训练先进的医疗多模态大模型提供了坚实的基础。 MedTrinity-25M的构建过程融合了多种技术,包括精细的数据处理、元数据整合、大规模语言模型(MLLM)辅助描述生成等,显着提高了数据的可用性和研究价值。
来自UCSC-VLAA 团队的“MedTrinity-25M” 大规模多模态数据集正式发布。这个数据集包含2500万张医学影像及详细注释。在医学领域中可谓是一次重要的创新,它拥有多粒度的注释,可以帮助研究人员更好地理解和应用医疗数据,用于训练医疗多模态大模型。
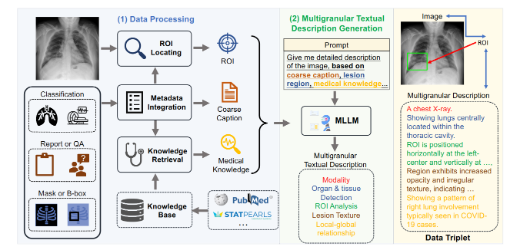
MedTrinity-25M 的构建过程相当复杂,团队经过精心的数据处理,提取了从各类数据中获得的关键信息,整合了元数据,生成了粗略的标题,定位了感兴趣的区域,还收集了相关的医学知识。更有意思的是,他们利用这些信息,利用大规模语言模型(MLLM)生成了细致的描述。这种方法不仅提高了数据的可用性,也为医学研究开辟了新的方向。
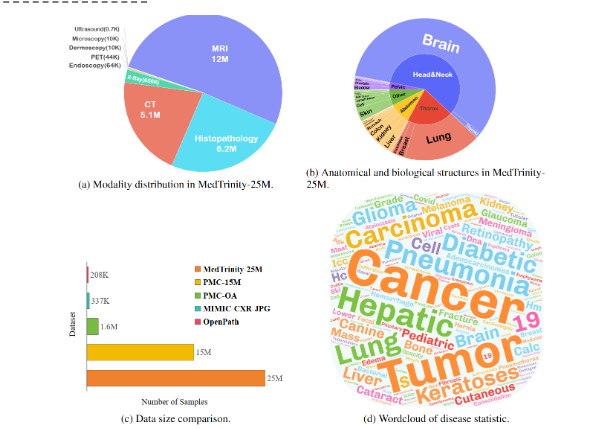
说到发布进程,值得一提的是,MedTrinity-25M 的Demo 数据集早在2024年6月就已经上线了,而完整数据集则是在7月21日正式对外发布,最近在8月7日,他们还发布了相关的论文。
除了数据集本身,团队还提供了一系列预训练的模型,像是LLaVA-Med++,这些模型在多个医学任务中表现出色。研究者们能够利用这些工具,更好地完成他们的项目,让医学研究效率大大提升。
MedTrinity-25M 为医学界提供了一个宝贵的资源,希望大家能够充分利用这个数据集,推动医学研究的发展。
项目入口:https://top.aibase.com/tool/medtrinity-25m
MedTrinity-25M数据集及其配套模型的发布,为医学人工智能研究提供了强大的助力。 我们期待该数据集能够促进医学影像分析、疾病诊断等领域的突破性进展,最终惠及更多患者。 欢迎各位研究者访问项目入口,深入了解并利用这一宝贵资源。