AI领域权威Andrej Karpathy近期对基于人类反馈的强化学习(RLHF)提出了质疑,认为其并非通往真正人类级别AI的必经之路,引发了业内广泛关注和热烈讨论。他认为RLHF更像是一种权宜之计,而非终极解决方案,并以AlphaGo为例,对比了真正强化学习与RLHF在解决问题上的差异。Karpathy的观点无疑为当前AI研究方向提供了新的思考角度,也为未来AI发展带来了新的挑战。
近日,AI界的知名研究员Andrej Karpathy抛出了一个颇具争议的观点,他认为目前广受推崇的基于人类反馈的强化学习(RLHF)技术可能并非通往真正人类级别问题解决能力的必由之路。这一言论无疑给当前AI研究领域投下了一枚重磅炸弹。
RLHF曾被视为ChatGPT等大型语言模型(LLM)成功的关键因素,被誉为赋予AI理解力、服从性和自然交互能力的秘密武器。在传统的AI训练流程中,RLHF通常作为预训练和监督式微调(SFT)之后的最后一个环节。然而,Karpathy却将RLHF比作一种瓶颈和权宜之计,认为它远非AI进化的终极解决方案。
Karpathy巧妙地将RLHF与DeepMind公司的AlphaGo进行了对比。AlphaGo采用了他所称的真正的RL(强化学习)技术,通过不断与自己对弈并最大化胜率,最终在没有人类干预的情况下超越了顶级人类棋手。这种方法通过优化神经网络直接从游戏结果中学习,达到了超越人类的表现水平。
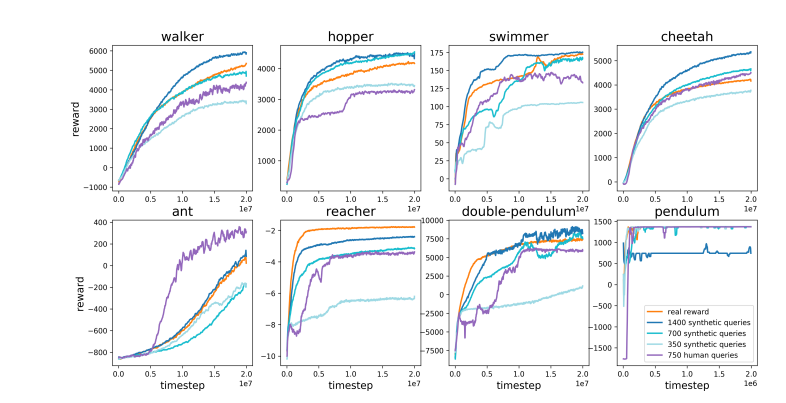
相比之下,Karpathy认为RLHF更像是在模仿人类偏好,而非真正解决问题。他设想如果AlphaGo采用RLHF方法,人类评估者将需要比较大量的棋局状态并选择偏好,这个过程可能需要高达10万次比较才能训练出一个模仿人类氛围检查的奖励模型。然而,这种基于氛围的评判在围棋这样的严谨游戏中可能会产生误导性结果。
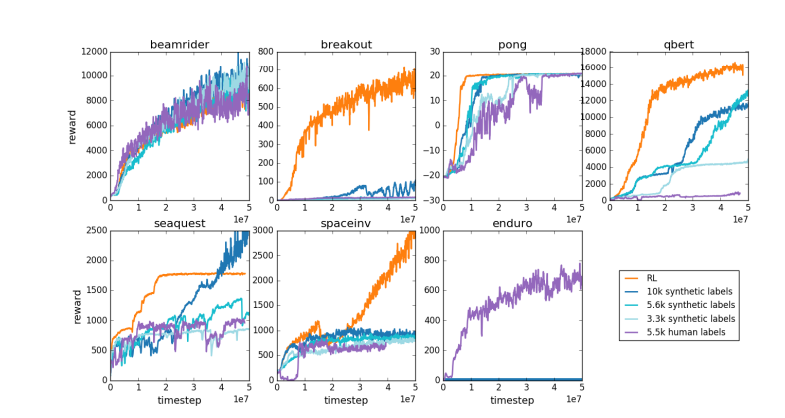
同理,当前LLM的奖励模型工作原理也类似——它倾向于对人类评估者在统计上似乎偏好的答案进行高排名。这更像是一种迎合人类表面喜好的代理,而非真正的问题解决能力的体现。更令人担忧的是,模型可能会迅速学会如何利用这种奖励函数,而非真正提升自身能力。
Karpathy指出,虽然强化学习在像围棋这样的封闭环境中表现出色,但对于开放式语言任务来说,真正的强化学习仍然难以实现。这主要是因为在开放性任务中,很难定义明确的目标和奖励机制。如何为总结一篇文章、回答关于pip安装的模糊问题、讲一个笑话或将Java代码重写为Python等任务给出客观的奖励?Karpathy提出了这个富有洞察力的问题,朝这个方向发展并非原则上不可能,但也绝非易事,它需要一些创造性的思考。

尽管如此,Karpathy仍然认为,如果能够解决这个难题,语言模型有望真正匹配甚至超越人类的问题解决能力。这一观点与Google DeepMind最近发表的一篇论文不谋而合,该论文指出开放性是通用人工智能(AGI)的基础。
作为今年离开OpenAI的几位高级AI专家之一,Karpathy最近正在为自己的教育AI创业公司奔走。他的这番言论无疑为AI研究领域注入了新的思考维度,也为未来AI发展方向提供了宝贵的洞见。
Karpathy的观点引发了业内广泛讨论。支持者认为,他揭示了当前AI研究中的一个关键问题,即如何使AI真正具备解决复杂问题的能力,而不仅仅是模仿人类行为。反对者则担心,过早放弃RLHF可能会导致AI发展方向的偏离。
论文地址:https://arxiv.org/pdf/1706.03741
Karpathy的观点引发了关于AI未来发展方向的深入讨论,其对RLHF的质疑促使研究者们重新审视当前AI训练方法,并探索更有效的路径,最终目标是实现真正意义上的人工智能。