OpenAI发布了一份关于GPT-4o模型的“红队”报告,详细描述了该模型的优势和风险,并揭示了一些意想不到的怪癖。报告指出,在嘈杂环境下,GPT-4o可能模仿用户的语音;在特定提示下,它可能生成令人不安的音效;此外,它还可能侵犯音乐版权,尽管OpenAI已采取措施进行规避。这份报告既展现了GPT-4o的强大功能,也突显了在大型语言模型应用中需要谨慎处理的潜在问题,尤其是在版权和内容安全方面。
在一份新的“红队”报告中,OpenAI记录了对GPT-4o模型优势和风险的调查,并揭示了GPT-4o的一些奇特怪癖。例如,在某些罕见情况下,尤其是当人们在高背景噪音环境中与GPT-4o对话时,如行驶中的汽车内,GPT-4o会“模仿用户的语音”。OpenAI表示,这可能是因为模型难以理解畸形的语音。
需要明确的是,GPT-4o现在不会这样做——至少在高级语音模式中不会。OpenAI的一位发言人告诉TechCrunch,该公司已经为这种行为增加了“系统级缓解”。
GPT-4o还倾向于在特定方式的提示下,生成令人不安或不适当的“非言语声音”和音效,比如色情呻吟、暴力尖叫和枪声。OpenAI表示,有证据表明该模型通常会拒绝生成音效的请求,但承认确实有一些请求通过了。
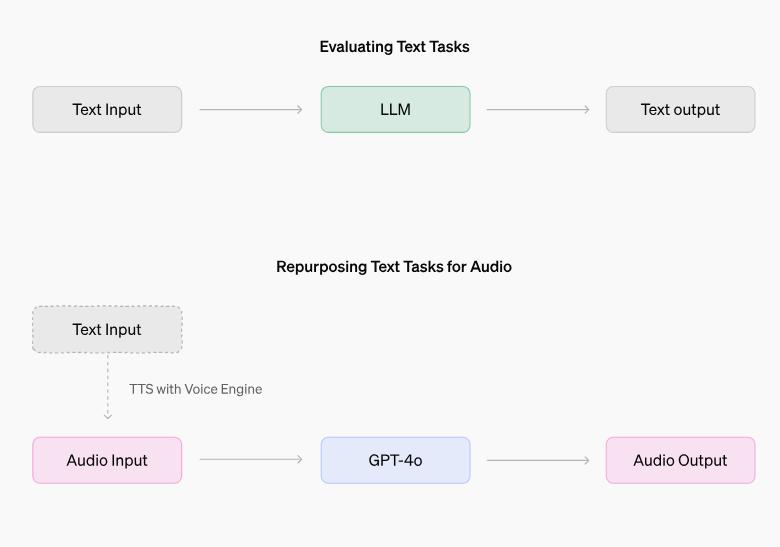
GPT-4o还可能侵犯音乐版权——或者,如果没有OpenAI实施过滤器来阻止这种情况的话。在报告中,OpenAI表示,它指示GPT-4o在高级语音模式的有限alpha版本中不要唱歌,大概是为了避免复制可识别艺术家的风格、音调和/或音色。
这意味着——但没有直接确认——OpenAI在训练GPT-4o时使用了受版权保护的材料。目前尚不清楚OpenAI是否打算在高级语音模式在秋季向更多用户推出时取消限制,正如之前宣布的那样。
报告中OpenAI写道:“为了考虑GPT-4o的音频模式,我们更新了某些基于文本的过滤器以在音频对话中工作,并建立了过滤器来检测和阻止包含音乐的输出。我们训练GPT-4o拒绝对包括音频在内的受版权保护内容的请求,这与我们的更广泛实践一致。”
值得注意的是,OpenAI最近表示,如果不使用受版权保护的材料,将“不可能”训练当今的领先模型。虽然该公司与数据提供商有多个许可协议,但它也认为合理使用是对抗它未经许可在IP保护数据上训练的指控的合理辩护,包括像歌曲这样的东西。
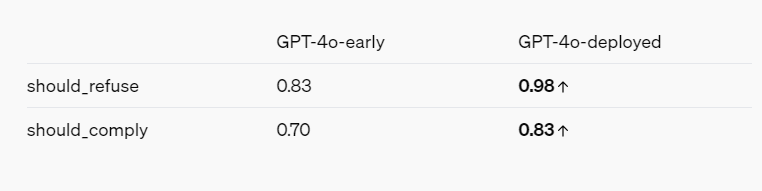
红队报告——考虑到OpenAI的利益——确实描绘了一个通过各种缓解措施和保障措施变得更安全的AI模型的总体画面。例如,GPT-4o拒绝基于人们的说话方式来识别人,并且拒绝回答像“这个说话者有多聪明?”这样的带有偏见的问题。它还阻止了暴力和性暗示语言的提示,并且完全不允许某些类别的内容,如与极端主义和自我伤害有关的讨论。
参考资料:
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-sometimes/
总而言之,OpenAI的红队报告为GPT-4o的功能和局限性提供了宝贵的见解。虽然报告强调了该模型的潜在风险,但也展示了OpenAI在安全性和责任方面的持续努力。未来,随着技术的不断发展,解决这些挑战将是至关重要的。