在蓬勃发展的AI领域,数据获取方式正日益成为焦点。本文探讨了AI公司Anthropic旗下的Claude团队因大规模数据抓取行为引发的争议。Claude团队的爬虫程序ClaudeBot在未经授权的情况下,对多个网站进行大量数据抓取,不仅违反了网站的规定,还造成了服务器资源的巨大消耗,引发了广泛的批评和担忧。此事件凸显了AI发展与数据版权保护之间的矛盾,引发了业界对数据获取伦理和法律规范的重新思考。
事件的起因是Claude团队的爬虫在24小时内对某公司服务器进行了100万次访问,以不付费的形式抓取网站内容。这一行为不仅明目张胆地无视了网站的禁止爬取公告,还强行占用了大量服务器资源。
受害公司尽管尽力进行了防御,但最终未能阻止Claude团队的数据抓取。公司负责人愤怒地在社交媒体上发声,谴责Claude团队的行为。许多网友也表达了他们的不满,有人甚至建议用偷这个词来描述这种行为。
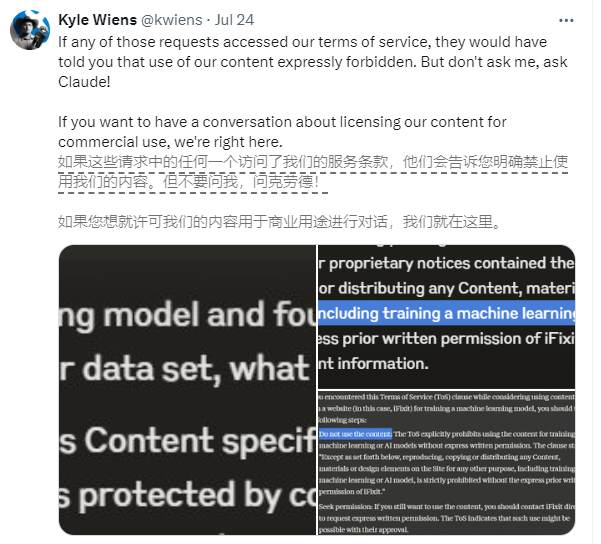
涉事的公司是iFixit,一家美国电子商务和操作指南网站。iFixit提供数百万个页面的免费在线维修指南,涵盖消费电子产品和小工具。然而,iFixit发现Claude的爬虫程序ClaudeBot在短时间内发起了大量请求,一天内访问了10TB的文件,整个5月份总计访问了73TB。
iFixit的CEO Kyle Wiens表示,ClaudeBot未经许可就偷走了他们的所有数据,并占用了服务器资源。尽管iFixit在其网站上明确声明禁止未经许可的数据抓取,但Claude团队似乎对此视而不见。
Claude团队的行为并非个例。今年4月,Linux Mint论坛也曾遭受ClaudeBot的频繁访问,导致论坛运行缓慢甚至崩溃。此外,还有声音指出,除了Claude和OpenAI的GPT以外,还有许多其他AI公司也在无视网站的robots.txt设置,强行抓取数据。
面对这种情况,有人建议网站所有者在页面中添加带有可追踪或独特信息的虚假内容,以检测数据是否被非法抓取。iFixit实际上已经采取了这一措施,并发现他们的数据不仅被Claude,还被OpenAI抓取。
这一事件引发了关于AI公司数据抓取行为的广泛讨论。一方面,AI的发展确实需要大量数据作为支撑;另一方面,数据抓取也应尊重网站所有者的权益和规定。如何在推动技术进步和保护版权之间找到平衡点,是整个行业需要思考的问题。
Claude团队的数据抓取事件敲响了警钟,提醒AI公司在追求技术进步的同时,必须尊重知识产权,遵守法律法规,并积极探索合规的数据获取途径。只有这样,才能确保AI技术的健康发展,避免因不当行为而损害行业声誉和公众信任。