英伟达近日发布了Minitron系列小型语言模型,包含4B和8B两个版本。此举旨在降低大型语言模型的训练和部署成本,让更多开发者能够轻松使用这项先进技术。 Minitron模型通过“修剪”和“知识蒸馏”技术,在显着缩小模型规模的同时,保持了与大型模型相当的性能,甚至在某些指标上超越了其他知名模型。这对于推动人工智能技术普及具有重要意义。
最近,英伟达(NVIDIA)在人工智能领域又有了新动作,他们推出了Minitron 系列的小型语言模型,包含4B 和8B 两个版本。这些模型不仅让训练速度提高了整整40倍,还能让开发者更轻松地使用它们进行各种应用,比如翻译、情感分析和对话AI 等。
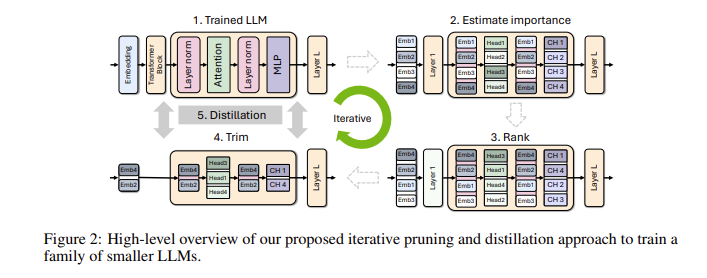
你可能会问,为什么小型语言模型这么重要呢?其实,传统的大型语言模型虽然性能强劲,但它们的训练和部署成本非常高,常常需要大量的计算资源和数据。为了能让更多的人能用得起这些先进技术,英伟达的研究团队想出了一个绝妙的办法:结合“修剪”(pruning)和“知识蒸馏”(knowledge distillation)两种技术,来高效地减小模型的规模。
具体来说,研究人员首先会从已有的大型模型出发,对其进行修剪。他们会评估模型中每个神经元、层或注意力头的重要性,并把那些不太重要的部分去掉。这样一来,模型就变得小巧了很多,训练时所需的资源和时间也大大减少。接下来,他们还会用一个小规模的数据集对修剪后的模型进行知识蒸馏训练,从而恢复模型的准确性。令人惊喜的是,这个过程不仅省钱,还能提高模型的性能!
在实际测试中,英伟达的研究团队在Nemotron-4模型家族上取得了很好的成果。他们成功将模型大小减少了2到4倍,同时保持了相似的性能。更令人兴奋的是,8B 模型在多个指标上超过了其他知名模型,如Mistral7B 和LLaMa-38B,并且在训练过程中所需的训练数据少了整整40倍,计算成本节省了1.8倍。想象一下,这意味着什么?更多的开发者可以用更少的资源和成本,体验到强大的AI 能力!
英伟达将这些优化过的Minitron 模型开源在Huggingface 上,供大家自由使用。
demo入口:https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
划重点:
** 提升训练速度**:Minitron 模型训练速度比传统模型快40倍,让开发者省时省力。
** 节省成本**:通过修剪和知识蒸馏技术,大幅降低训练所需的计算资源和数据量。
? ** 开源共享**:Minitron 模型已在Huggingface 上开源,更多人能轻松获取和使用,推动AI 技术普及。
Minitron模型的开源,标志着小型语言模型在实际应用中的一个重要突破,也预示着人工智能技术将更加普及和易于使用,为更多开发者和应用场景赋能。未来,我们可以期待更多类似的创新,推动人工智能技术不断发展。