OpenAI发布了新一代推理模型o3及其精简版o3-mini,它们是o1系列的继任者,旨在通过更深入的思考来提高回答问题的准确性。 o3在ARC-AGI基准测试中取得了突破性进展,展现出接近人类水平的问题求解能力。 o3-mini则侧重于速度和成本效益,尤其适合编程任务。虽然o3系列模型不会直接公开发布,但OpenAI已开放给安全研究人员进行预览。
o3模型在多个基准测试中表现出色,例如在SWE-bench Verified基准上的准确率比o1提高了20%以上,在竞赛数学和GPQA Diamond上的准确率也显着提升。 OpenAI还引入了“审议式对齐”的新安全评估方法,用于确保模型的安全性和对安全规范的遵守。目前,OpenAI正在进行外部安全测试,并已开放早期访问申请。
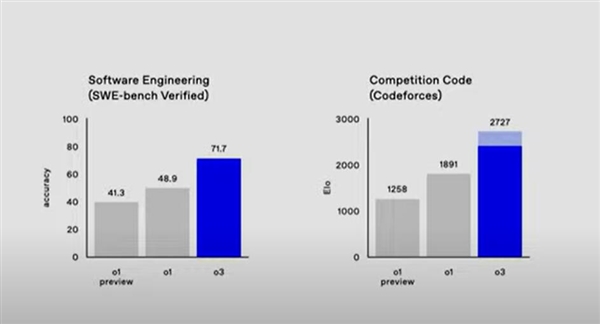
在编程和数学问题解决方面,o3模型展现了显着的能力。在SWE-bench Verified基准上,o3的准确率约为71.7%,比o1模型高出20%以上。在Competition Code中,o3获得了2727Elo得分,而o1仅为1891。此外,o3在竞赛数学上的准确率达到96.7%,在GPQA Diamond上的准确率达到87.7%,比o1高出近10%。
OpenAI还介绍了一种新的安全评估方法——deliberative alignment,即审议式对齐,这是一种直接教授模型安全规范的新范式,并可训练模型在回答前明确回忆规范并准确地执行推理。这种方法被用于对齐OpenAI的o系列模型,并实现了对OpenAI安全政策的高度精确遵守。
目前,OpenAI正在推进外部安全测试,并已在网站上开放早期访问申请,申请者需填写在线表格并提供相关信息。选定的研究人员将被授予访问o3和o3-mini的权限,以探索它们的能力并为安全评估做出贡献。
OpenAI o3系列模型的发布标志着人工智能推理能力的显着提升,其在多个领域的出色表现预示着未来AI技术发展的新方向。 未来,我们将持续关注o3系列模型的进展和应用。