阿里巴巴通义千问团队发布了Qwen2系列开源模型,该系列包含5个尺寸的预训练和指令微调模型,参数数量和性能较前一代Qwen1.5有显着提升。 Qwen2系列在多语言能力方面也取得了重大突破,支持27种除英语和中文以外的其他语言。在自然语言理解、编码、数学能力等方面,大型模型(70B+参数)表现出色,尤其Qwen2-72B模型在性能和参数数量上超越了前一代。此次发布标志着人工智能技术的新高度,为全球AI应用和商业化提供了更广阔的可能性。
今天凌晨,阿里巴巴通义千问团队发布了Qwen2系列开源模型。该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。关键信息显示,这些模型的参数数量和性能较前一代Qwen1.5有显着提升。
对于模型的多语言能力,Qwen2系列投入了大量精力增加数据集的数量和质量,覆盖英语和中文以外的27种其他语言。经过对比测试,大型模型(70B + 参数)在自然语言理解、编码、数学能力等方面表现出色,Qwen2-72B 模型更在性能和参数数量方面超越前一代。
Qwen2模型不仅在基础语言模型评估中展现出强大的能力,还在指令调优模型评估中获得令人瞩目的成绩。其多语言能力在M-MMLU 和MGSM 等基准测试中表现出众,展现出Qwen2指令调优模型的强大潜力。
此次发布的Qwen2系列模型标志着人工智能技术的新高度,为全球AI 应用和商业化提供了更广阔的可能性。展望未来,Qwen2将进一步扩展模型规模和多模式能力,加速推动开源AI 领域的发展。
模型信息Qwen2系列包含5种尺寸的基础和指令调优型号,包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B、Qwen2-72B。我们在下表中说明了各型号的关键信息:
楷模Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# 参数0.49亿1.54亿7.07B57.41B72.71B# 非Emb 参数0.35亿1.31B5.98亿56.32亿70.21B质量保证真的真的真的真的真的领带嵌入真的真的错误的错误的错误的上下文长度3.2万3.2万128千64千128千具体来说,之前在Qwen1.5中,只有Qwen1.5-32B 和Qwen1.5-110B 采用了Group Query Attention(GQA)。这次,我们针对所有模型大小都应用了GQA,以便它们在模型推理中享受更快的速度和更少内存占用的好处。对于小模型,我们更喜欢应用tying embedding,因为大型稀疏embedding 占了模型总参数的很大一部分。
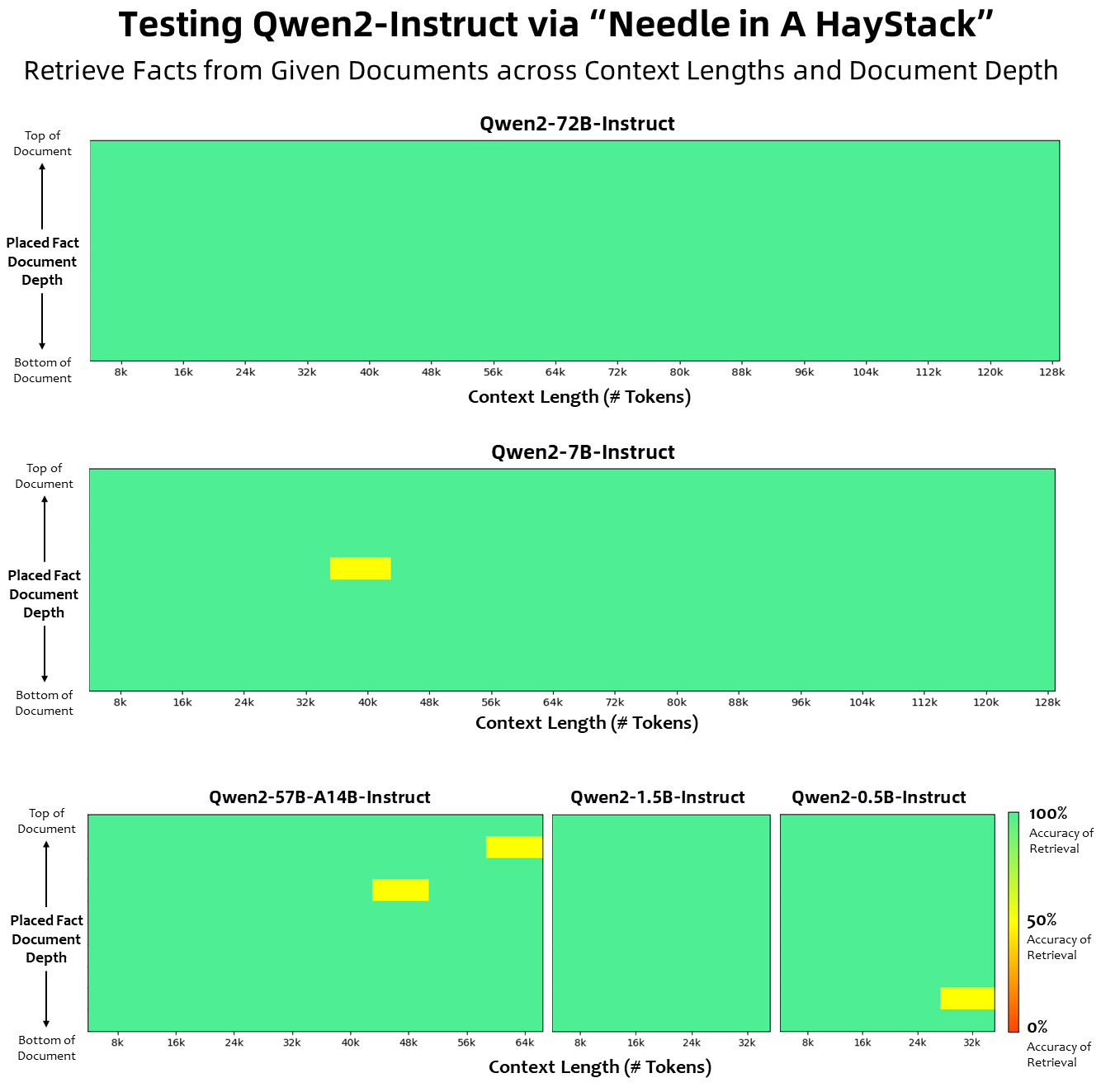
在上下文长度方面,所有基础语言模型均已在32K 个token 的上下文长度数据上进行了预训练,我们在PPL 评估中观察到高达128K 的令人满意的外推能力。但是,对于指令调整模型,我们并不满足于仅仅进行PPL 评估;我们需要模型能够正确理解长上下文并完成任务。在表中,我们列出了指令调整模型的上下文长度能力,这些能力是通过对Needlein a Haystack任务的评估来评估的。值得注意的是,当使用YARN 进行增强时,Qwen2-7B-Instruct 和Qwen2-72B-Instruct 模型都表现出令人印象深刻的能力,可以处理高达128K 个token 的上下文长度。
我们付出了巨大的努力来增加预训练和指令调整数据集的数量和质量,这些数据集涵盖了英语和中文以外的多种语言,以增强其多语言能力。尽管大型语言模型具有推广到其他语言的固有能力,但我们明确强调在我们的训练中加入了27种其他语言:
区域语言西欧德语, 法语, 西班牙语, 葡萄牙语, 意大利语, 荷兰语东欧和中欧俄语、捷克语、波兰语中东阿拉伯语、波斯语、希伯来语、土耳其语东亚日语、韩语东南亚越南语、泰语、印尼语、马来语、老挝语、缅甸语、宿务语、高棉语、他加禄语南亚印地语、孟加拉语、乌尔都语此外,我们投入了大量精力来解决多语言评估中经常出现的代码转换问题。因此,我们的模型处理这种现象的能力显着提高。使用通常会引发跨语言代码转换的提示进行的评估证实,相关问题显着减少。
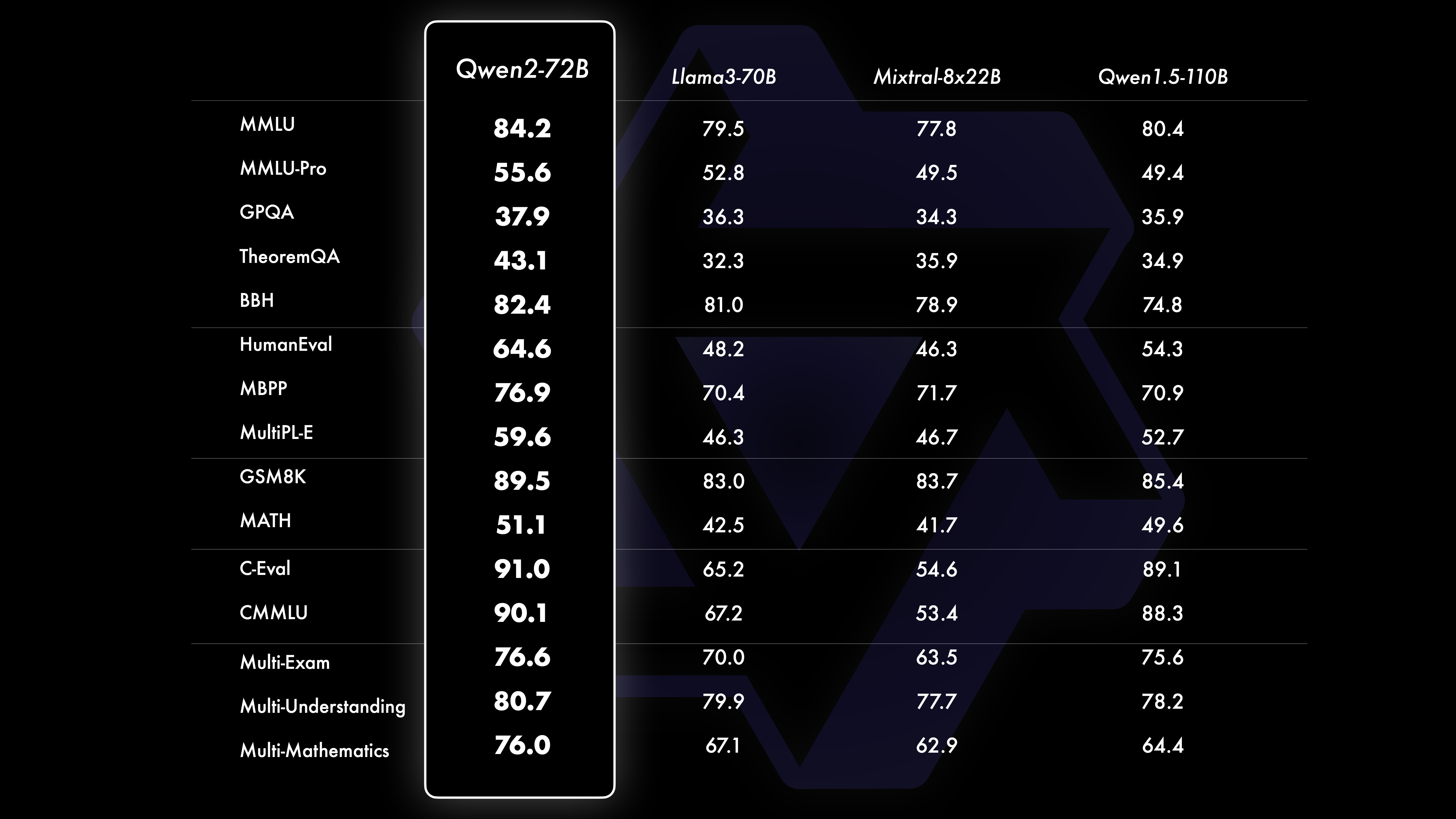
表现对比测试结果显示,大规模模型(70B+参数)的性能相比Qwen1.5有大幅提升。本次测试以大规模模型Qwen2-72B为中心。在基础语言模型方面,我们对比了Qwen2-72B和当前最佳的开放模型在自然语言理解、知识获取、编程能力、数学能力、多语言能力等能力方面的性能。得益于精心挑选的数据集和优化的训练方法,Qwen2-72B的表现优于Llama-3-70B等领先模型,在参数数量较少的情况下,其性能甚至超过了上一代Qwen1.5- 110B。
在进行大量大规模预训练之后,我们进行后训练,以进一步增强Qwen 的智能,使其更接近人类。此过程进一步提高了模型在编码、数学、推理、指令遵循、多语言理解等领域的能力。此外,它使模型的输出与人类价值观保持一致,确保其有用、诚实且无害。我们的后训练阶段采用可扩展训练和最少人工注释的原则设计。具体而言,我们研究如何通过各种自动对齐策略获得高质量、可靠、多样化和创造性的演示数据和偏好数据,例如数学的拒绝抽样、编码和指令遵循的执行反馈、创意写作的反向翻译、角色扮演的可扩展监督等。至于训练,我们采用了监督微调、奖励模型训练和在线DPO 训练的组合。我们还采用了一种新颖的在线合并优化器来最大限度地减少对齐税。这些共同努力大大提高了我们模型的能力和智能,如下表所示。
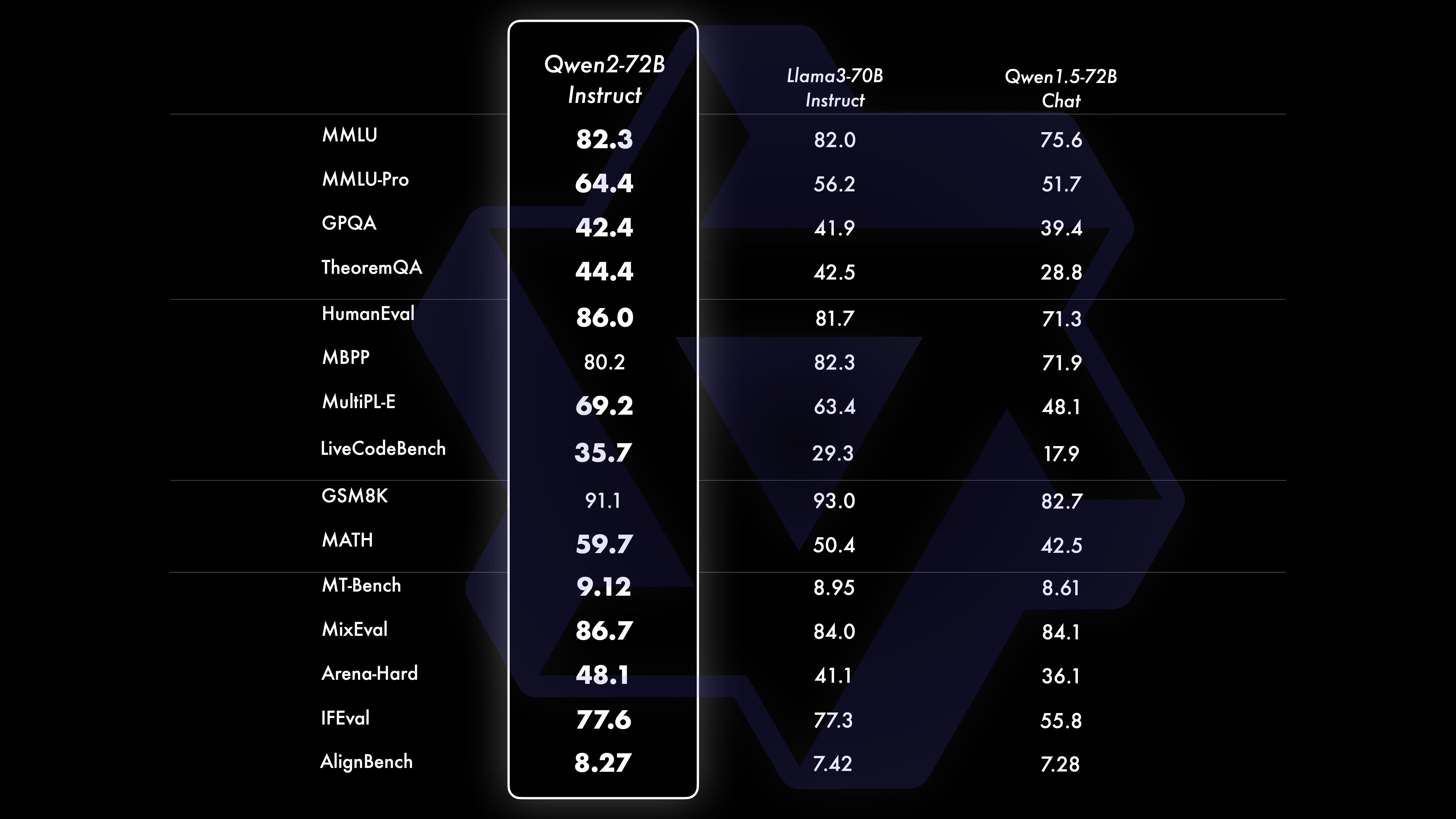
我们对Qwen2-72B-Instruct 进行了全面评估,涵盖了各个领域的16个基准测试。 Qwen2-72B-Instruct 在获得更好的能力和与人类价值观保持一致之间取得了平衡。具体来说,Qwen2-72B-Instruct 在所有基准测试中都明显优于Qwen1.5-72B-Chat,并且与Llama-3-70B-Instruct 相比也达到了具有竞争力的性能。
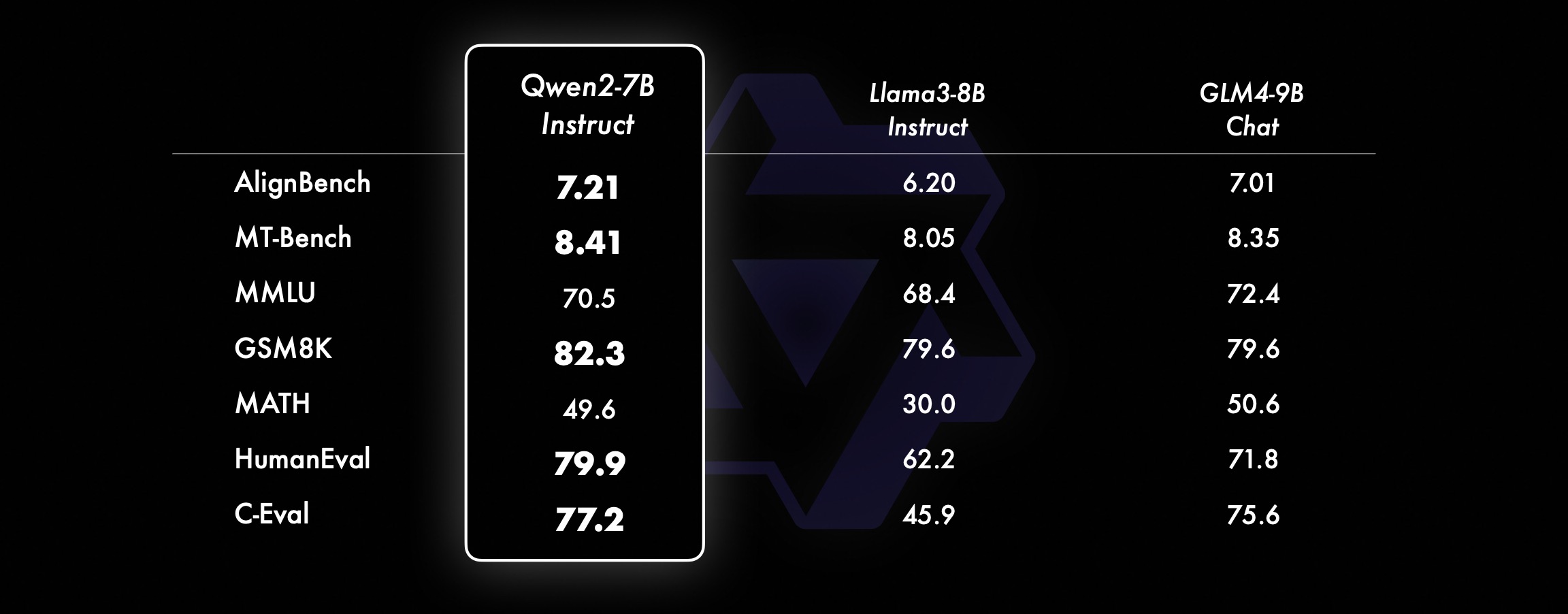
在较小的模型上,我们的Qwen2模型也优于类似甚至更大尺寸的SOTA 模型。与刚刚发布的SOTA 模型相比,Qwen2-7B-Instruct 仍然在各个基准测试中表现出优势,特别是在编码和中文相关指标上表现出色。
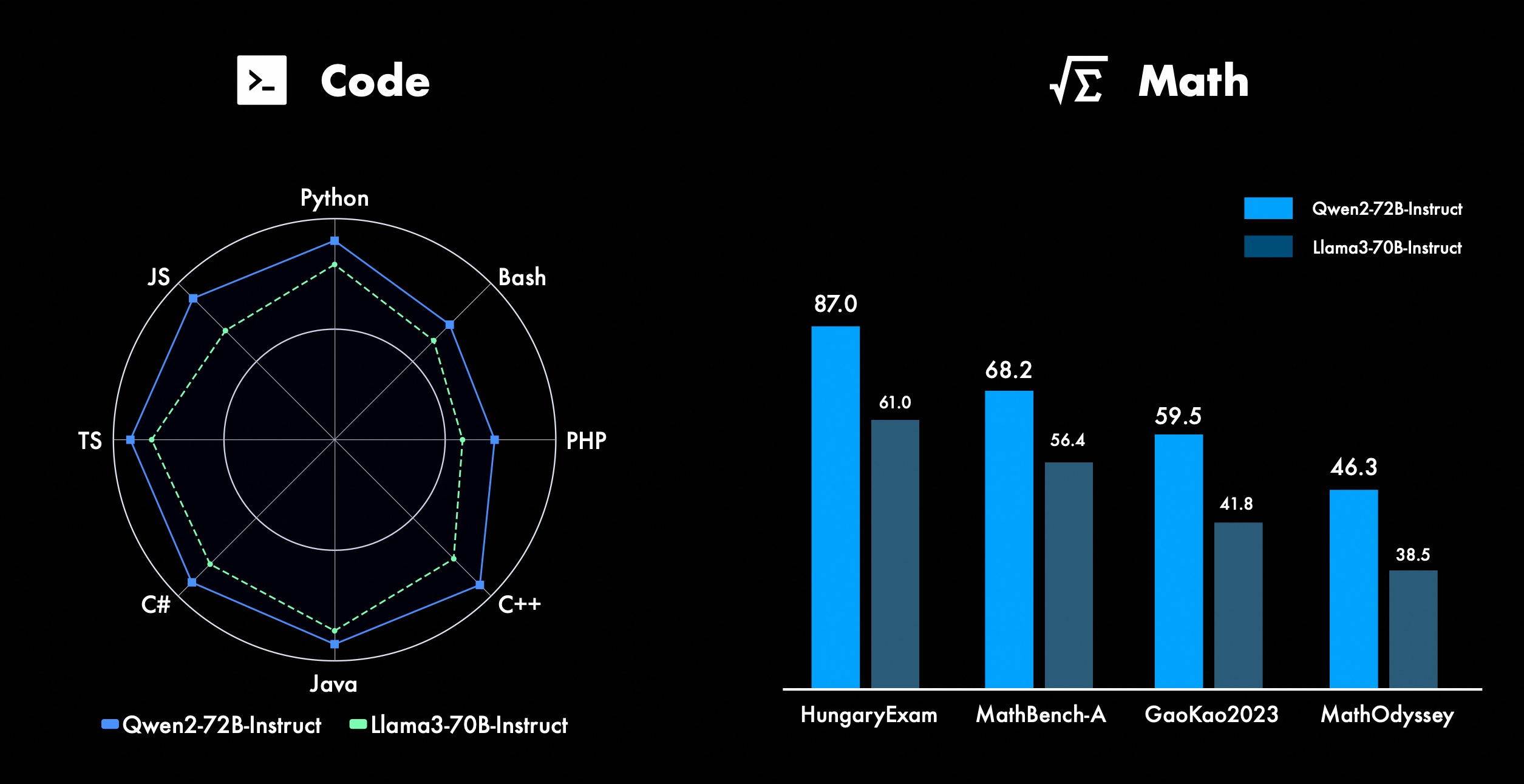
我们一直致力于提升Qwen 的高级功能,特别是在编码和数学方面。在编码方面,我们成功整合了CodeQwen1.5的代码训练经验和数据,从而使Qwen2-72B-Instruct 在各种编程语言方面取得了显着的改进。在数学方面,通过利用广泛且高质量的数据集,Qwen2-72B-Instruct 在解决数学问题方面体现出了更强的能力。
在Qwen2中,所有指令调整模型都在32k 长度上下文中进行了训练,并使用YARN或Dual Chunk Attention等技术推断到更长的上下文长度。
下图是我们在Needle in a Haystack上的测试结果,值得注意的是,Qwen2-72B-Instruct 能够完美处理128k 上下文中的信息提取任务,再加上其与生俱来的强大性能,在资源充足的情况下,它成为处理长文本任务的首选。
此外,值得注意的是该系列其他型号的令人印象深刻的功能:Qwen2-7B-Instruct 几乎完美地处理长达128k 的上下文,Qwen2-57B-A14B-Instruct 管理长达64k 的上下文,而该系列中的两个较小的型号支持32k 的上下文。
除了长上下文模型之外,我们还开源了一个代理解决方案,用于高效处理包含多达100万个标记的文档。有关更多详细信息,请参阅我们关于此主题的专门博客文章。
下表展示了大型模型针对四类多语言不安全查询(非法活动、欺诈、色情、隐私暴力)产生的有害响应占比。测试数据来自Jailbreak,并翻译成多种语言进行评估。我们发现Llama-3无法有效处理多语言提示,因此未将其纳入比较范围。通过显着性检验(P_value),我们发现Qwen2-72B-Instruct 模型在安全性方面的表现与GPT-4相当,并且显着优于Mistral-8x22B 模型。
语言非法活动欺诈罪色情隐私暴力GPT-4米斯特拉尔-8x22BQwen2-72B-指导GPT-4米斯特拉尔-8x22BQwen2-72B-指导GPT-4米斯特拉尔-8x22BQwen2-72B-指导GPT-4米斯特拉尔-8x22BQwen2-72B-指导中文0%13%0%0%17%0%43%47%53%0%10%0%英文0%7%0%0%23% 0%37%67%63%0%27%3%应收账0%13%0%0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%法国0%3%0%3%3%7%3%19%7%0%27%0%柯0%4%0%3 %8%4%17%29%10%0%26%4%点0%7%0%3%7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4%11%0%22%26%22%0%0%0%平均的0%8%0% 3%11%2%27%39%31%3%16%2%使用Qwen2进行开发目前所有模型均已在Hugging Face 和ModelScope 中发布,欢迎访问模型卡查看详细使用方法,并进一步了解每个模型的特性、性能等信息。
长期以来,有很多朋友支持着Qwen 的发展,包括微调(Axolotl、Llama-Factory、Firefly、Swift、XTuner)、量化(AutoGPTQ、AutoAWQ、Neural Compressor)、部署(vLLM、SGL、SkyPilot、TensorRT-LLM、 OpenVino、TGI)、API 平台(Together、Fireworks、OpenRouter)、本地运行(MLX、Llama.cpp、Ollama、LM Studio)、Agent 和RAG 框架(LlamaIndex、CrewAI、OpenDevin)、评估(LMSys、OpenCompass、Open LLM Leaderboard)、模型训练(Dolphin、Openbuddy)等。关于如何将Qwen2与第三方框架一起使用,请参考各自的文档以及我们的官方文档。

还有很多团队和个人为Qwen 做出了贡献,我们并没有提及。我们衷心感谢他们的支持,并希望我们的合作能够促进开源AI 社区的研究和发展。
执照这次,我们将模型的许可改为不同的。 Qwen2-72B 及其指令调优模型仍使用原有的Qianwen License,而其他所有模型,包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B 和Qwen2-57B-A14B,均转而采用Apache2.0 !我们相信,我们模型对社区的进一步开放可以加速Qwen2在全球的应用和商业化。
Qwen2的下一步是什么?我们正在训练更大的Qwen2模型,以进一步探索模型扩展以及我们最近的数据扩展。此外,我们将Qwen2语言模型扩展为多模式,能够理解视觉和音频信息。在不久的将来,我们将继续开源新模型以加速开源AI。敬请期待!
引用我们即将发布Qwen2的技术报告。欢迎引用!
@article{qwen2,附录基础语言模型评估基础模型的评测主要关注自然语言理解、一般问答、编码、数学、科学知识、推理、多语言能力等模型性能。
评估的数据集包括:
英语任务:MMLU(5次)、MMLU-Pro(5次)、GPQA(5次)、Theorem QA(5次)、BBH(3次)、HellaSwag(10次)、Winogrande(5次)、TruthfulQA( 0次)、ARC-C(25次)
编码任务:EvalPlus(0-shot)(HumanEval、MBPP、HumanEval+、MBPP+)、MultiPL-E(0-shot)(Python、C++、JAVA、PHP、TypeScript、C#、Bash、JavaScript)
数学任务:GSM8K (4次)、MATH (4次)
中文任务:C-Eval(5-shot)、CMMLU (5-shot)
多语言任务:多考试(M3Exam5次、IndoMMLU3次、ruMMLU5次、mMMLU5次)、多理解(BELEBELE5次、XCOPA5次、XWinograd5次、XStoryCloze0次、PAWS-X5次)、多数学(MGSM8次)、多翻译(Flores-1015次)
Qwen2-72B 性能数据集DeepSeek-V2Mixtral-8x22B骆驼-3-70BQwen1.5-72BQwen1.5-110BQwen2-72B建筑学教育部教育部稠密稠密稠密稠密#已激活参数21B39B70B72B110B72B#参数236B140B70B72B110B72B英语莫尔曼·卢78.577.879.577.580.484.2MMLU-专业版-49.552.845.849.455.6质量保证-34.336.336.335.937.9定理问答-35.932.329.334.943.1百比黑78.978.981.065.574.882.4希拉斯瓦格87.888.788.086. 087.587.6大窗户84.885.085.383.083.585.1ARC-C70.070.768.865.969.668.9诚实问答42.251.045.659.649.654.8编码人力评估45.746.348.246.354.364.6马来西亚公共服务局73.971.770.466.970.976.9评估55.054.154.852.957.765.4多种的44.446.746.341.852.759.6数学GSM8K79.283.783.079.585.489.5数学43.641.742.534.149.651.1中国人C-评估81.754.665.284.189.191.0加拿大蒙特利尔大学84.053 .467.283.588.390.1多种语言多项考试67.563.570.066.475.676.6多方理解77.077.779.978.278.280.7多元数学58.862.967.161.764.476.0多翻译36.023.338.035.636.237.8Qwen2-57B-A14B数据集贾巴Mixtral-8x7B仪-1.5-34BQwen1.5-32BQwen2-57B-A14B建筑学教育部教育部稠密稠密教育部#已激活参数12B12B34B32B14B#参数52B47B34B32B57B英语莫尔曼·卢67.471.877.174.376.5MMLU -专业版-41.048.344.043.0质量保证-29.2-30.834.3定理问答-23.2-28.833.5百比黑45.450.376.466.867.0希拉斯瓦格87.186.585.985.085.2维诺格兰德82.581.984.981 .579.5ARC-C64.466.065.663.664.1诚实问答46.451.153.957.457.7编码人力评估29.337.246.343.353.0马来西亚公共服务局-63.965.564.271.9评估-46.451.950.457.2多种的-39.039.538.549 .8数学GSM8K59.962.582.776.880.7数学-30.841.736.143.0中国人C-评估---83.587.7加拿大蒙特利尔大学--84.882.388.5多种语言多项检查-56.158.361.665.5多方理解-70.773.976.577.0多元数学-45.049.356.162.3多翻译-29.830.033.534.5Qwen2-7B数据集米斯特拉尔-7B杰玛-7B骆驼-3-8BQwen1.5-7BQwen2-7B# 参数7.2B8.5亿8.0B7.7B7.6B# 非emb 参数7.0B7.8亿7.0B6.5亿6.5亿英语莫尔曼·卢64.264.666.661.070.3MMLU-专业版30.933.735.429.940.0质量保证24.725 .725.826.731.8定理问答19.221.522.114.231.1百比黑56.155.157.740.262.6希拉斯瓦格83.282.282.178.580.7维诺格兰德78.479.077.471.377.0ARC-C60.061.159.354.260.6诚实问答42.244 .844.051.154.2编码人力评估29.337.233.536.051.2马来西亚公共服务局51.150.653.951.665.9评估36.439.640.340.054.2多种的29.429.722.628.146.3数学GSM8K52.246.456.062.579.9数学13.124.320.520.344.2中国人C-评估47.443.649.574.183.2加拿大蒙特利尔大学--50.873.183.9多种语言多项检查47.142.752.347.759.2多方理解63.358.368.667.672.0多元数学26.339.136.337.357.5多翻译23.331.231.928.431.5Qwen2 -0.5B 和Qwen2-1.5B数据集披-2杰玛-2B最低每千次展示费用Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B#非Emb 参数2.5亿2.0B2.4B1.3B0.35亿1.3 B莫尔曼·卢52.742.353.546.845.456.5MMLU-专业版-15.9--14.721.8定理问答----8.915.0人力评估47.622.050.020.122.031.1马来西亚公共服务局55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5数学3.511.810.210.110.721.7百比黑43.435.236.924.228.437.2希拉斯瓦格73.171.468.361.449.366.6维诺格兰德74.466.8-60.356.866.2ARC -C61.148.5-37.931.543.9诚实问答44.533.1-39.439.745.9C-评估23.428.051.159.758.270.6加拿大蒙特利尔大学24.2-51.157.855.170.3指令调整模型评估Qwen2-72B-指导数据集骆驼- 3-70B-指导Qwen1.5-72B-聊天Qwen2-72B-指导英语莫尔曼·卢82.075.682.3MMLU-专业版56.251.764.4质量保证41.939.442.4定理问答42.528.844.4MT-Bench8.958.619.12竞技场-困难41.136.148.1IFEval(提示严格访问)77.355.877.6编码人力评估81.771.386.0马来西亚公共服务局82.371.980.2多种的63.448.169.2评估75.266.979.0活码测试29.317.935.7数学GSM8K93.082.791. 1数学50.442.559.7中国人C-评估61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-指导数据集Mixtral-8x7B-Instruct-v0.1Yi-1.5-34B-聊天Qwen1.5-32B-聊天Qwen2- 57B-A14B-指导建筑学教育部稠密稠密教育部#已激活参数12B34B32B14B#参数47B34B32B57B英语莫尔曼·卢71.476.874.875.4MMLU-专业版43.352.346.452.8质量保证--30.834.3定理问答- -30.933.1MT-Bench8.308.508.308.55编码人力评估45.175.268.379.9马来西亚公共服务局59.574.667.970.9多种的--50.766.4评估48.5-63.671.6活码测试12.3-15.225.5数学GSM8K65.790.283.679.6数学30.750.142.449.1中国人C-评估--76.780.5AlignBench5.707.207.197.36Qwen2-7B-指导数据集骆驼-3-8B-指导Yi-1.5-9B-聊天GLM-4- 9B-聊天Qwen1.5-7B-聊天Qwen2-7B-指导英语莫尔曼·卢68.469.572.459.570.5MMLU-专业版41.0--29.144.1质量保证34.2--27.825.3定理问答23.0--14.125 .3MT-Bench8.058.208.357.608.41编码人道主义62.266.571.846.379.9马来西亚公共服务局67.9--48.967.2多种的48.5--27.259.1评估60.9--44.870.3活码测试17.3-- 6.026.6数学GSM8K79.684.879.660.382.3数学30.047.750.623.249.6中国人C-评估45.9-75.667.377.2AlignBench6.206.907.016.207.21Qwen2-0.5B-Instruct 和Qwen2-1.5B-Instruct数据集Qwen1. 5-0.5B-聊天Qwen2-0.5B-指导Qwen1.5-1.8B-聊天Qwen2-1.5B-指导莫尔曼·卢35.037.943.752.4人力评估9.117.125.037.8GSM8K11.340.135.361.6C-评估37.245.255.363.8IFEval(提示严格访问)14.620.016.829.0指令调整模型的多语言能力我们在几个跨语言开放基准以及人工评估中将Qwen2指令调整模型与其他最近的LLM 进行了比较。对于基准,我们在2个评估数据集上展示了结果:
Okapi 的M-MMLU:多语言常识评估(我们用ar、de、es、fr、it、nl、ru、uk、vi、zh 的子集进行评估)MGSM:对德语、英语、西班牙语、法语、日语、俄语、泰国语、中文和巴西语等语言进行数学评估结果根据每个基准测试的语言平均得出,如下所示:
楷模M-MMLU(5次发射)MGSM(0次射击,CoT)专有法学硕士GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6克劳德-3-作品- 2024022980.191.0克劳德-3-十四行诗-2024022971.085.6开源法学硕士command-r-plus-110b65.563.5Qwen1.5-7B-聊天50.037.0Qwen1.5-32B-聊天65.065.0Qwen1.5 -72B-聊天68.471.7Qwen2-7B-指导60.057.0Qwen2-57B-A14B-指导68.074.0Qwen2-72B-指导78.086.6对于人工评估,我们使用内部评估集将Qwen2-72B-Instruct 与GPT3.5、GPT4和Claude-3-Opus 进行比较,其中包括10种语言ar、es、fr、ko、th、vi、pt、id 、ja 和ru(分数范围从1~5):
楷模应收账西文法国柯日六点ID贾汝平均的克劳德-3-作品-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.393.724.324.09 GPT-4-Turbo-04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-指导3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.553.923.943.873.833.953.553.773.063.633.71GPT- 3.5-Turbo-11062.524.073.472.373.382.903.373.562.753.243.16按任务类型分组,结果如下:
楷模知识理解创建数学克劳德-3-作品-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-指导3.414.074.363.61GPT-4-06133.424. 094.103.32GPT-3.5-Turbo-11063.373.673.892.97这些结果证明了Qwen2指令调整模型强大的多语言能力。
阿里巴巴此次开源的Qwen2系列模型,在性能和多语言能力上均有显着提升,为开源AI社区贡献了重要力量。未来,Qwen2将持续发展,进一步扩展模型规模和多模式能力,值得期待。