視覺字幕
v1.0
Visual Captions字幕工具,VisualCaptions是新推出的一款強大的字幕工具,可以為使用者的工作會議改進更多字幕的顯示,更方便地實現辦公室交流。有需要的用戶快來加入其中吧。
谷歌在人機互動頂級會議ACM CHI(Conference on Human Factors in Computing Systems)上展示了一個系統Visual Captions,介紹了遠端會議中的一個全新視覺解決方案,可以在對話背景中生成或檢索圖片以提高對方對複雜或陌生概念的了解。
Visual Captions 系統基於微調後的大型語言模型,可在開放詞彙的對話中主動推薦相關的視覺元素,並已融入開源專案ARChat 中。
在使用者研究中,研究人員邀請了實驗室內的26 位參與者,與實驗室外的10 位參與者對系統進行評估,超過80% 的使用者基本上都認同Video Captions 可以在各種場景下能提供有用、有意義的視覺推薦,並且可以提升交流體驗。
在開發之前,研究人員首先邀請了10 位內部參與者,包括軟體工程師、研究人員、UX 設計師、視覺藝術家、學生等技術與非技術背景的從業者,討論對即時視覺增強服務的特定需求和期望。
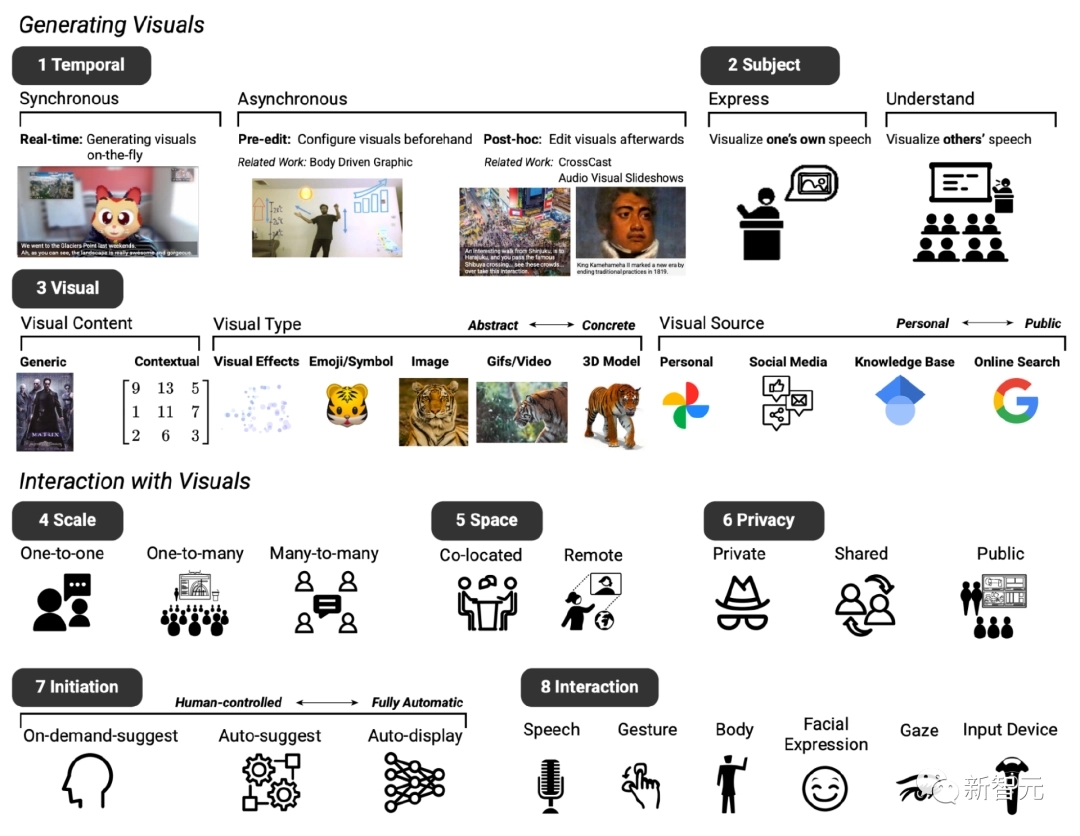
兩次會議後,根據現有的文字轉圖像系統,確立了預期原型系統的基本設計,主要包括八個維度(記為D1 至D8)。
D1:時序,視覺增強系統可與對話同步或非同步展現
D2:主題,可用於表達和理解語音內容
D3:視覺,可使用廣泛的視覺內容、視覺類型和視覺來源
D4:規模,依會議規模的不同,視覺增強效果可能有所不同
D5:空間,視訊會議是在同一地點還是在遠端設定中
D6:隱私,這些因素也影響視覺效果是否應該私下顯示、在參與者之間分享或向所有人公開
D7:初始狀態,參與者還確定了他們希望在進行對話時與系統交互的不同方式,例如,不同級別的“主動性”,即用戶可以自主確定係統何時介入聊天D8:交互,參與者設想了不同的互動方法,例如,使用語音或手勢進行輸入