bitnet.cpp 是 1 位元 LLM 的官方推理架構(例如 BitNet b1.58)。它提供了一套最佳化的內核,支援 CPU 上 1.58 位元模型的快速無損推理(接下來將支援 NPU 和 GPU)。
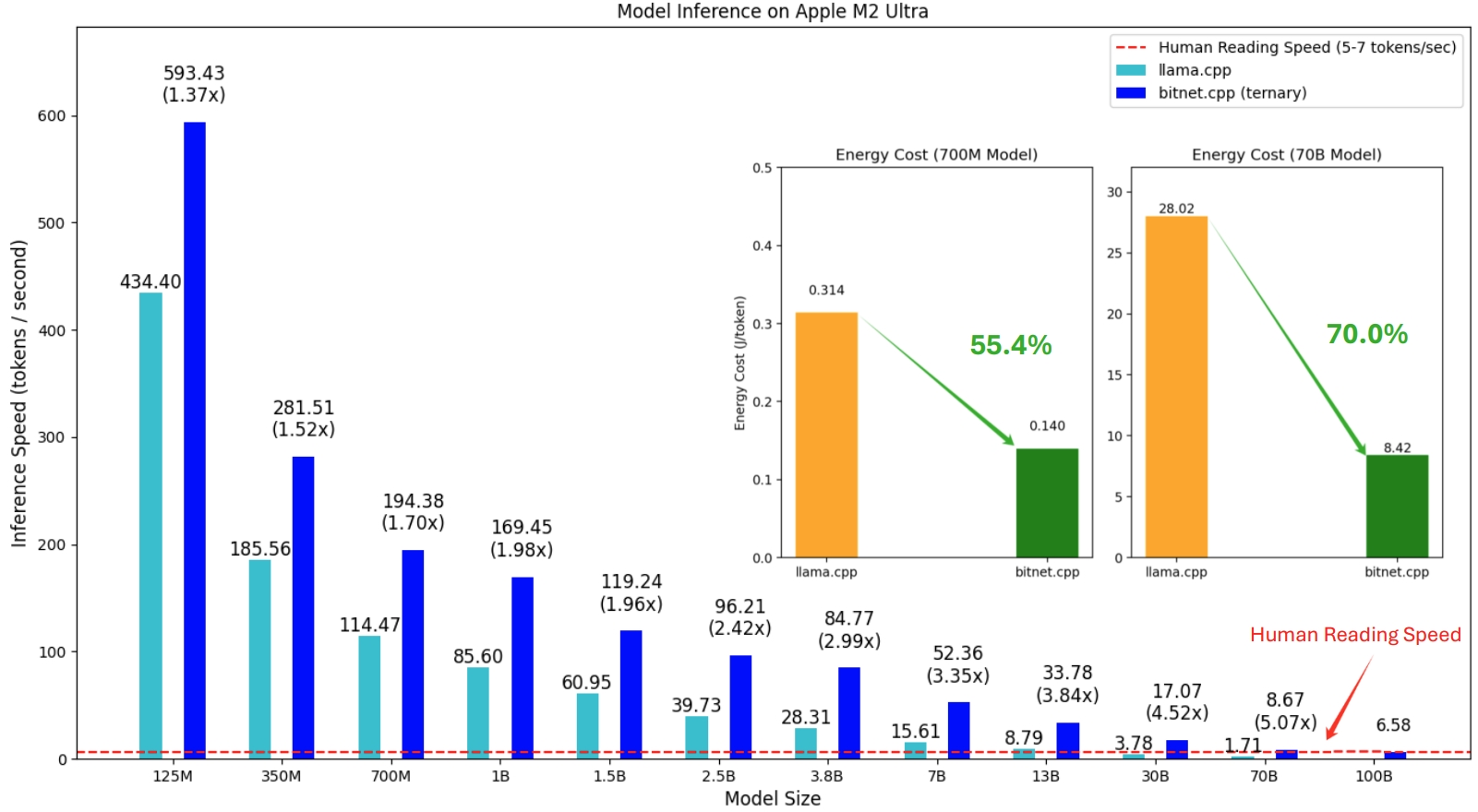
bitnet.cpp 的第一個版本是支援 CPU 上的推理。 bitnet.cpp 在 ARM CPU 上實現了1.37 倍到5.07 倍的加速,較大的模型獲得了更大的效能提升。此外,它還能將能耗降低55.4%至70.0% ,進一步提高整體效率。在 x86 CPU 上,加速範圍為2.37 倍至6.17 倍,能耗降低71.9%至82.2% 。此外,bitnet.cpp 可以在單一 CPU 上運行 100B BitNet b1.58 模型,實現與人類閱讀相當的速度(每秒 5-7 個令牌),從而顯著增強在本地設備上運行 LLM 的潛力。更多詳情請參閱技術報告。


測試的模型是在研究環境中使用的虛擬設置,用於演示 bitnet.cpp 的推理性能。
在 Apple M2 上運行 BitNet b1.58 3B 模型的 bitnet.cpp 演示:
2024 年 10 月 21 日 1 位元 AI 基礎架構:第 1.1 部分,快速無損 BitNet b1.58 CPU 推理
2024 年 10 月 17 日 bitnet.cpp 1.0 發布。
03/21/2024 1 位法學碩士時代__Training_Tips_Code_FAQ
02/27/2024 1 位法學碩士時代:所有大型語言模型均採用 1.58 位
2023 年 10 月 17 日 BitNet:為大型語言模型擴展 1 位元 Transformer
該項目基於llama.cpp框架。我們要感謝所有作者對開源社群的貢獻。此外,bitnet.cpp 的核心建構在 T-MAC 中首創的查找表方法之上。對於三元模型之外的一般低位元 LLM 的推理,我們建議使用 T-MAC。
❗️我們使用 Hugging Face 上現有的 1 位 LLM 來示範 bitnet.cpp 的推理功能。這些模型既不是由微軟訓練也不是由微軟發布的。我們希望 bitnet.cpp 的發布能夠在模型大小和訓練代幣方面激發大規模環境中 1 位 LLM 的開發。
| 模型 | 參數 | 中央處理器 | 核心 | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-大 | 0.7B | x86 | ✔ | ✘ | ✔ |
| 手臂 | ✔ | ✔ | ✘ | ||
| 位元網_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| 手臂 | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-代幣 | 8.0B | x86 | ✔ | ✘ | ✔ |
| 手臂 | ✔ | ✔ | ✘ | ||
蟒蛇>=3.9
cmake>=3.22
叮噹>=18
使用 C++ 進行桌面開發
適用於 Windows 的 C++-CMake 工具
適用於 Windows 的 Git
適用於 Windows 的 C++-Clang 編譯器
MS-Build 對 LLVM 工具集的支援 (clang)
對於 Windows 用戶,安裝 Visual Studio 2022。
對於 Debian/Ubuntu 用戶,您可以使用自動安裝腳本進行下載
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
康達(強烈推薦)
重要的
如果您使用的是 Windows,請記住始終使用 VS2022 的開發人員命令提示字元/PowerShell 來執行下列命令
克隆儲存庫
git clone --recursive https://github.com/microsoft/BitNet.gitcd BitNet
安裝依賴項
#(建議)建立新的conda環境conda create -n bitnet-cpp python=3.9 conda 啟動 bitnet-cpp pip install -r 要求.txt
建構專案
# 從Hugging Face 下載模型,將其轉換為量化的gguf 格式,並建立專案python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# 或者您可以手動下載模型並建置使用本機 pathhuggingface-cli 下載 HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens 運行 python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s
用法: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}s [--modelD. --log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--使用預調整]
設定運行推理的環境
可選參數:
-h, --help 顯示此說明訊息並退出
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1.58-10B-tokens}, -hr {1bitLLM/bitnet_b1_58-D11851255,13000,000,00,000,000,15,000,155,155,121858545,100,00,000,15,15,000,1FFFle1545545,1215 月8B-1.58-100B-代幣}
用於推理的模型
--模型目錄 MODEL_DIR, -md MODEL_DIR
儲存/載入模型的目錄
--log-dir LOG_DIR, -ld LOG_DIR
保存日誌資訊的目錄
--quant-type {i2_s,tl1}, -q {i2_s,tl1}
量化類型
--quant-embd 將嵌入量化為 f16
--use-pretuned, -p 使用預先調整的核心參數# 使用量化模型運行推理 python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel 回到花園。Mary 去了廚房。Sandra桑德拉去了廚房。瑪麗去了廚房。桑德拉走向廚房。桑德拉走到走廊。約翰走進臥室。瑪麗回到花園。瑪麗在哪裡?
用法: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
運行推理
可選參數:
-h, --help 顯示此說明訊息並退出
-m 模型,--模型模型
模型檔案的路徑
-n N_PREDICT, --n-預測 N_PREDICT
產生文字時要預測的標記數量
-p 提示,--提示提示
提示生成文本
-t 線程, --threads 線程
使用的線程數
-c CTX_SIZE, --ctx-size CTX_SIZE
提示上下文的大小
-temp 溫度,--temp 溫度
溫度,控制生成文字隨機性的超參數我們提供腳本來執行提供模型的推理基準測試。
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
以下是每個論點的簡要解釋:
-m , --model :模型檔案的路徑。這是運行腳本時必須提供的必要參數。
-n , --n-token :推理過程中產生的標記數量。它是一個可選參數,預設值為 128。
-p , --n-prompt :用於產生文字的提示標記的數量。這是一個可選參數,預設值為 512。
-t , --threads :用於運行推理的執行緒數。它是一個可選參數,預設值為 2。
-h , --help : 顯示幫助訊息並退出。使用此參數來顯示使用資訊。
例如:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
此指令將使用位於/path/to/model模型執行推理基準測試,利用 4 個執行緒從 256 個令牌提示產生 200 個令牌。
對於任何公共模型不支援的模型佈局,我們提供腳本來產生具有給定模型佈局的虛擬模型,並在您的電腦上執行基準測試:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# 使用產生的模型執行基準測試,使用-m 指定模型路徑,-p 指定處理的提示,-n 指定產生令牌的數量python utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128