幸泰衛門
v0.7.6
一個開源、乾淨且可自訂的 RAG UI,用於與您的文件聊天。建置時考慮到了最終用戶和開發人員。
現場演示 |線上安裝 |使用者指南 |開發者指南 |回饋 |接觸
該專案可作為功能性 RAG UI,適用於想要對其文件進行 QA 的最終用戶和想要建立自己的 RAG 管道的開發人員。
+------------------------------------------------ - --------------------------+|最終用戶:使用「kotaemon」建立的應用程式的使用者。 || (您使用類似於上面演示中的應用程式)|| +------------------------------------------------ - --------------+ || |開發者:那些用「kotaemon」建構的人。 | || | (您的專案中某處有「import kotaemon」)| || | +------------------------------------------------ - --+ | || | |貢獻者:那些讓「kotaemon」變得更好的人。 | | || | | (您對此存儲庫進行 PR)| | || | +------------------------------------------------ - --+ | || +------------------------------------------------ - --------------+ |+-------------------------------- - -------------------------------------------------- -----+
乾淨簡約的 UI :基於 RAG 的 QA 的使用者友善介面。
支援各種 LLM :與 LLM API 提供者(OpenAI、AzureOpenAI、Cohere 等)和本地 LLM(透過ollama和llama-cpp-python )相容。
易於安裝:簡單的腳本可讓您快速入門。
RAG 管道框架:用於建立您自己的基於 RAG 的文件 QA 管道的工具。
可自訂的 UI :使用使用 Gradio 建置的提供的 UI 查看 RAG 管道的運作情況。
Gradio 主題:如果您使用 Gradio 進行開發,請在此處查看我們的主題:kotaemon-gradio-theme。
託管您自己的文件 QA (RAG) Web UI :支援多用戶登入、在私人/公共收藏中組織您的文件、與他人協作並分享您最喜愛的聊天。
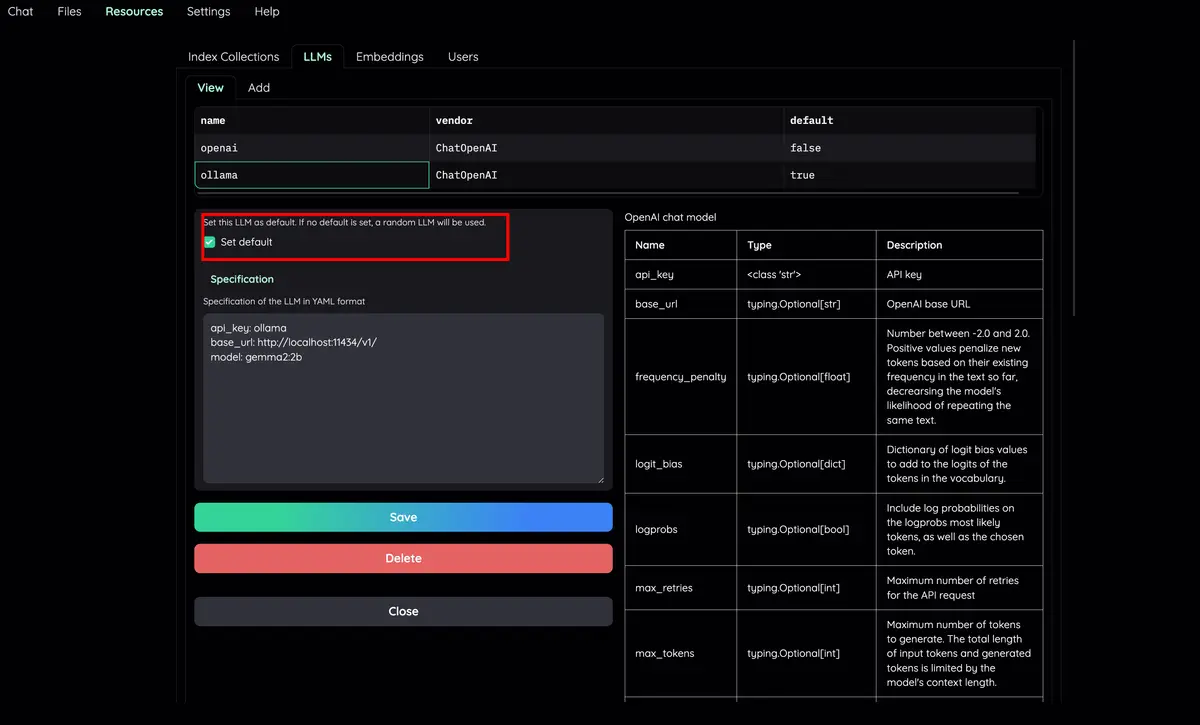
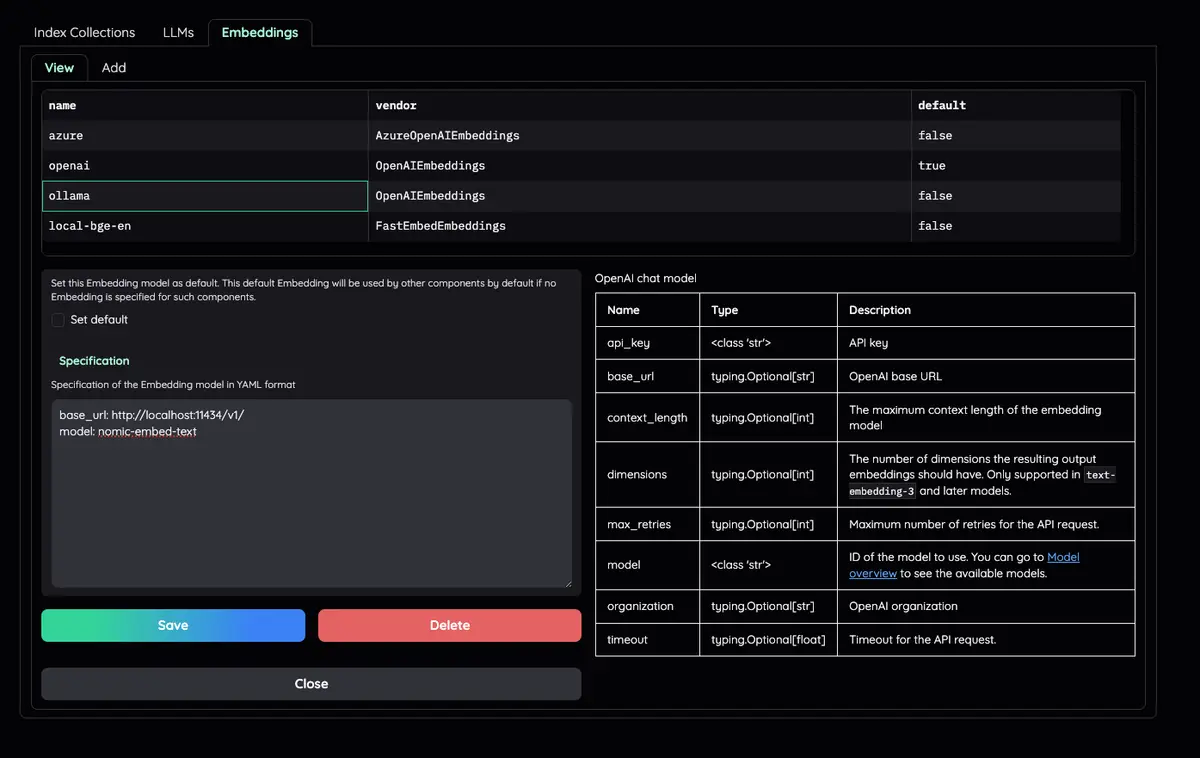
組織您的 LLM 和嵌入模型:支援本地 LLM 和流行的 API 提供者(OpenAI、Azure、Ollama、Groq)。
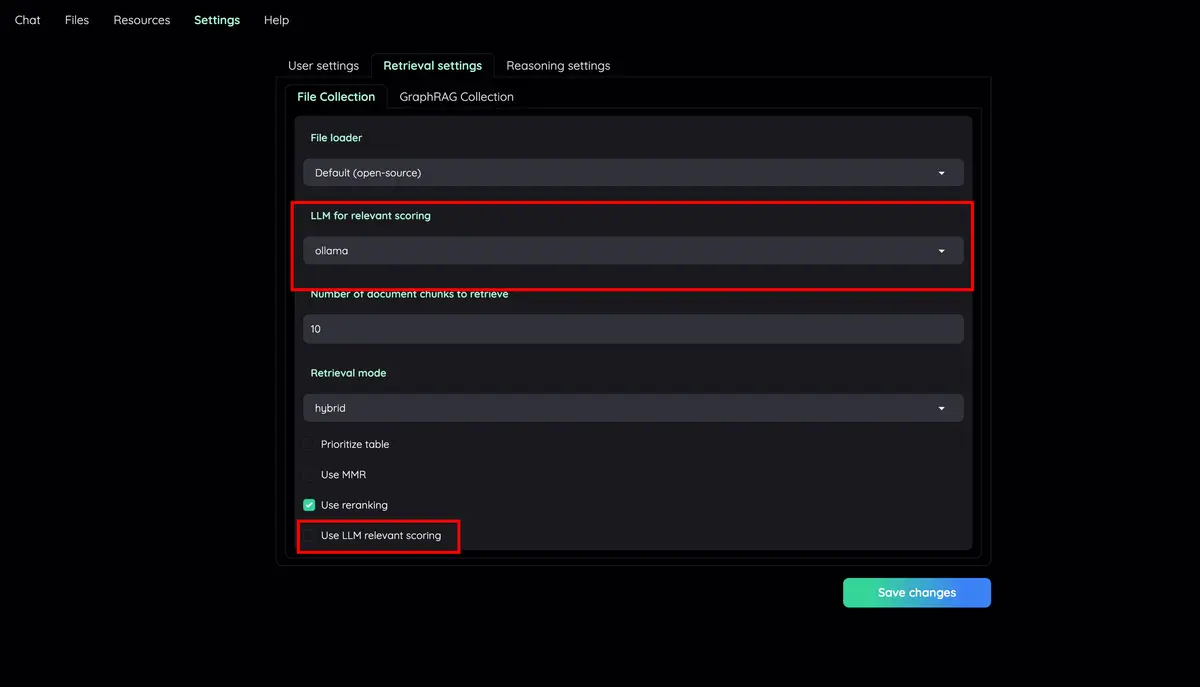
混合 RAG 管道:Sane 預設 RAG 管道具有混合(全文和向量)檢索器和重新排名,以確保最佳檢索品質。
多模式 QA 支援:透過圖形和表格支援對多個文件進行問答。支援多模式文件解析(UI 上的可選選項)。
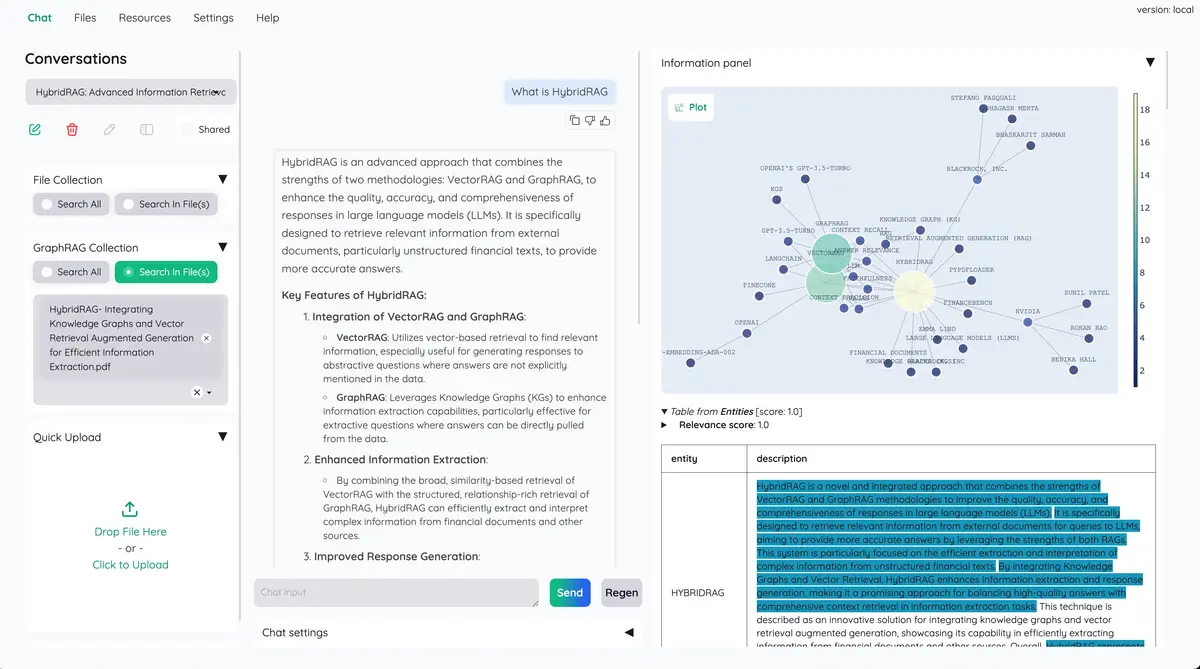
帶有文件預覽的高級引文:預設情況下,系統將提供詳細的引文,以確保LLM答案的正確性。直接在瀏覽器內的 PDF 檢視器中查看您的引文(包括相關分數)並反白顯示。當檢索管道返回低相關文章時發出警告。
支援複雜的推理方法:使用問題分解來回答您的複雜/多跳問題。使用ReAct 、 ReWOO和其他代理程式支援基於代理的推理。
可設定的設定 UI :您可以在 UI 上調整檢索和產生過程的最重要方面(包括提示)。
可擴展:基於 Gradio 構建,您可以根據需要自由定製或添加任何 UI 元素。此外,我們的目標是支援多種文件索引和檢索策略。 GraphRAG索引管道作為範例提供。
如果您不是開發人員而只想使用該應用程序,請查看我們易於遵循的用戶指南。下載最新版本的
.zip檔案以獲得所有最新功能和錯誤修復。
Python >= 3.10
Docker:可選,如果您使用 Docker 安裝
如果您想要處理.pdf 、 .html 、 .mhtml和.xlsx文件以外的文件,則為非結構化。安裝步驟因作業系統而異。請訪問該連結並按照其中提供的具體說明進行操作。
我們支援lite和full版的 Docker 映像。使用full ,還將安裝額外的unstructured軟體包,它可以支援其他檔案類型( .doc , .docx ,...),但代價是更大的 docker 映像大小。對於大多數用戶來說, lite映像在大多數情況下都應該運作良好。
使用lite版。
碼頭運行 -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-lite
要使用full版。
碼頭運行 -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-full
我們目前支援和測試兩個平台: linux/amd64和linux/arm64 (適用於較新的 Mac)。您可以透過在docker run命令中傳遞--platform來指定平台。例如:
# 使用 linux/arm64docker run 平台運行 docker -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm --平台linux/arm64 ghcr.io/cinnamon/kotaemon:main-lite
一切都設定正確後,您可以造訪http://localhost:7860/存取 WebUI。
我們使用GHCR來儲存docker映像,所有映像都可以在這裡找到。
在新的 python 環境中克隆並安裝所需的套件。
# 可選(設定環境)conda create -n kotaemon python=3.10 conda 啟動 kotaemon# 複製此 repogit 克隆 https://github.com/Cinnamon/kotaemoncd kotaemon pip install -e "libs/kotaemon[all]"pip install -e "libs/ktem"
在此專案的根目錄中建立一個.env檔。使用.env.example作為模板
.env檔案用於服務使用者希望在啟動應用程式之前預先配置模型的用例(例如,在 HF 集線器上部署應用程式)。該文件僅用於在第一次運行時填充資料庫一次,在後續運行中將不再使用。
(可選)要啟用瀏覽器內的PDF_JS檢視器,請下載 PDF_JS_DIST,然後將其解壓縮到libs/ktem/ktem/assets/prebuilt
啟動網頁伺服器:
蟒蛇應用程式.py
該應用程式將自動在您的瀏覽器中啟動。
預設使用者名稱和密碼都是admin 。您可以直接透過 UI 設定其他使用者。
檢查Resources選項卡以及LLMs and Embeddings ,並確保.env檔案中的api_key值設定正確。如果沒有設置,可以在那裡設置。
筆記
官方 MS GraphRAG 索引僅適用於 OpenAI 或 Ollama API。我們建議大多數用戶使用 NanoGraphRAG 實作來與 Kotaemon 直接整合。
安裝 nano-GraphRAG: pip install nano-graphrag
nano-graphrag安裝可能會引入版本衝突,請參閱此問題
快速修復: pip uninstall hnswlib chroma-hnswlib && pip install chroma-hnswlib
使用USE_NANO_GRAPHRAG=true環境變數啟動 Kotaemon。
在資源設定中設定預設的 LLM 和嵌入模型,NanoGraphRAG 會自動辨識它。
非 Docker 安裝:如果您不使用 Docker,請使用下列命令安裝 GraphRAG:
pip 安裝 graphrag 未來
設定 API KEY :若要使用 GraphRAG 檢索器功能,請確保設定GRAPHRAG_API_KEY環境變數。您可以直接在您的環境中執行此操作,也可以將其新增至.env檔案。
使用本機模型和自訂設定:如果您想將 GraphRAG 與本機模型(如Ollama )一起使用或自訂預設的 LLM 和其他配置,請將USE_CUSTOMIZED_GRAPHRAG_SETTING環境變數設為 true。然後,調整settings.yaml.example檔案中的設定。
請參閱本地模型設定。
預設情況下,所有應用程式資料都儲存在./ktem_app_data資料夾中。您可以備份或複製此資料夾以將安裝轉移到新電腦。
對於進階使用者或特定用例,您可以自訂這些檔案:
flowsettings.py
.env
flowsettings.py該檔案包含您的應用程式的配置。您可以使用此處的範例作為起點。
# 設定您的首選文件儲存(具有全文搜尋功能)KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)# 設定您的首選向量儲存(用於基於向量的搜尋)KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory | Qdrant)# 啟用啟用 | /停用多模式QAKH_REASONINGS_USE_MULTIMODAL=True# 設定新的推理管道或修改現有的推理管道。 .ReactAgentPipeline","ktem .reasoning.rewoo.RewooAgentPipeline", ]
.env此文件提供了另一種配置模型和憑證的方法。
或者,您可以透過.env檔案使用連接到 LLM 所需的資訊來設定模型。該檔案位於應用程式的資料夾中。如果您沒有看到它,您可以創建一個。
目前,支援以下提供者:
使用ollama OpenAI相容伺服器:
將GGUF與llama-cpp-python一起使用
您可以從 Hugging Face Hub 搜尋並下載要在本地運行的法學碩士。目前支援以下模型格式:
安裝 ollama 並啟動應用程式。
拉取您的模型,例如:
llama 拉 llama3.1:8b ollama 拉 nomic-embed-text
在 Web UI 上設定模型名稱並將其設為預設值:
GGUF
您應該選擇大小小於裝置記憶體的型號,並應保留 2 GB 左右的空間。例如,如果您總共有 16 GB RAM,其中 12 GB 可用,那麼您應該選擇最多 10 GB RAM 的型號。較大的模型往往會產生更好的生成效果,但也會花費更多的處理時間。
以下是一些建議及其在記憶體中的大小:
Qwen1.5-1.8B-Chat-GGUF:約2 GB
使用 Web UI 上提供的模型名稱新增新的 LlamaCpp 模型。
開放人工智慧
在.env檔案中,使用 OpenAI API 金鑰設定OPENAI_API_KEY變量,以便能夠存取 OpenAI 的模型。還有其他可以修改的變量,請隨意編輯它們以適合您的情況。否則,預設參數應該適用於大多數人。
OPENAI_API_BASE=https://api.openai.com/v1 OPENAI_API_KEY=<此處為您的 OpenAI API 金鑰>OPENAI_CHAT_MODEL=gpt-3.5-turbo OPENAI_EMBEDDINGS_MODEL=文字嵌入-ada-002
Azure 開放人工智慧
對於透過 Azure 平台的 OpenAI 模型,您需要提供 Azure 端點和 API 金鑰。您可能還需要提供聊天模型和嵌入模型的開發名稱,具體取決於您設定 Azure 開發的方式。
AZURE_OPENAI_ENDPOINT= AZURE_OPENAI_API_KEY= OPENAI_API_VERSION=2024-02-15-預覽 AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=文本嵌入-ada-002
本地型號
在此處檢查預設管道實作。您可以快速調整預設 QA 管道的工作方式。
在libs/ktem/ktem/reasoning/中新增新的.py實現,然後將其包含在flowssettings中以在 UI 上啟用它。
檢查libs/ktem/ktem/index/file/graph中的範例實現
(更多說明 WIP)。
由於我們的專案正在積極開發中,我們非常重視您的回饋和貢獻。請參閱我們的貢獻指南來開始。感謝我們所有的貢獻者!