Facebook Messenger Bot
1.0.0
我訓練的 FB Messenger 聊天機器人可以像我一樣說話。相關的部落格文章。
對於這個項目,我想根據我過去來自各個社交媒體網站的對話日誌訓練一個序列到序列模型。您可以在部落格文章中詳細了解此方法背後的動機、ML 模型的詳細資訊以及每個 Python 腳本的用途,但我想使用此自述文件來解釋如何訓練自己的聊天機器人像您一樣說話。
為了運行這些腳本,您需要以下程式庫。
以互動方式或在終端機中輸入以下內容,從 GitHub 下載並解壓縮整個儲存庫。
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.git導航到電腦上儲存庫的頂級目錄
cd Facebook-Messenger-Bot我們的第一項工作是從各種社群媒體網站下載您的所有對話資料。對我來說,我使用 Facebook、Google Hangouts 和 LinkedIn。如果您有其他網站可以從中獲取數據,那也沒有問題。您只需在 createDataset.py 中建立一個新方法。
Facebook 資料:從此處下載您的資料。下載後,您應該會有一個相當大的文件,名為messages.htm 。這將是一個相當大的文件(對我來說超過 190 MB)。我們需要解析這個大文件,並提取所有對話。為此,我們將使用 Dillon Dixon 善意開源的這個工具。您將繼續透過運行來安裝該工具
pip install fbchat-archive-parser然後運行:
fbcap ./messages.htm > fbMessages.txt這將為您提供一個相當統一的文本文件中的所有 Facebook 對話。謝謝狄龍!繼續,然後將該檔案儲存在您的 Facebook-Messenger-Bot 資料夾中。
LinkedIn 資料:從此處下載您的資料。下載後,您應該會看到一個inbox.csv檔案。我們不需要在這裡執行任何其他步驟,我們只需將其複製到我們的資料夾中即可。
Google Hangouts 資料:在此下載您的資料表。下載後,您將獲得一個我們需要解析的 JSON 檔案。為此,我們將使用透過這篇精彩部落格文章找到的解析器。我們希望將資料保存到文字檔案中,然後將該資料夾複製到我們的資料夾中。
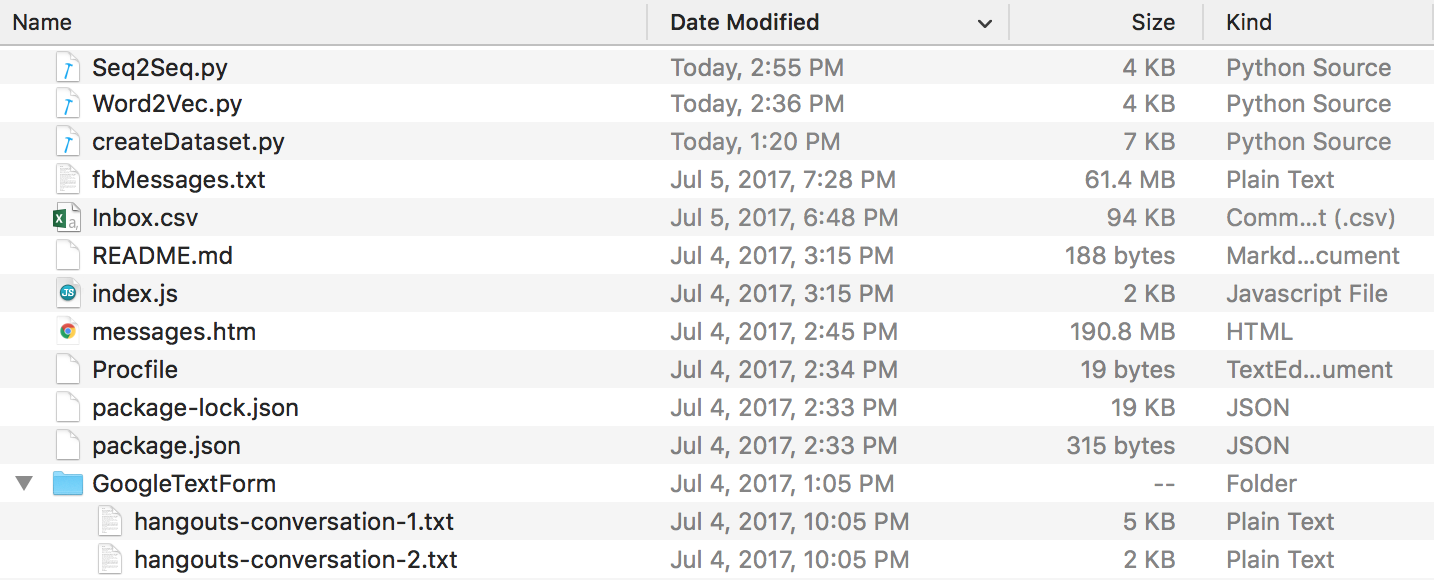
最後,您應該有一個如下所示的目錄結構。如果資料夾和檔案名稱不同,請確保重新命名。
Discord 數據:您可以使用 Tyrrrz 製作的這款很棒的 DiscordChatExporter 來提取您的 Discord 聊天日誌。按照其文件以.txt格式提取所需的單一聊天日誌(這很重要)。然後,您可以將它們全部放入儲存庫目錄中名為DiscordChatLogs的資料夾中。
WhatsApp 資料:確保您有手機,如果還沒有,請將其設定為美國日期格式(稍後當您將日誌檔案解析為 .csv 時,這一點很重要)。您不能使用 WhatsApp 網路來實現此目的。打開要發送的聊天,點擊選單按鈕,點擊“更多”,然後點擊“透過電子郵件發送聊天”。將電子郵件傳送給您自己並將其下載到您的電腦。這將為您提供一個 .txt 文件,為了解析它,我們將其轉換為 .csv。為此,請轉到此連結並輸入日誌檔案中的所有文字。點擊“匯出”,下載 csv 檔案並將其儲存在名稱為“whatsapp_chats.csv”的 Facebook-Messenger-Bot 資料夾中。
注意:上面連結中提供的解析器似乎已被刪除。如果您仍有格式正確的.csv文件,您仍可以使用該文件。否則,將您的 Whatsapp 聊天日誌下載為.txt文件,並將它們全部放入儲存庫目錄中名為WhatsAppChatLogs的資料夾中。當且僅當它找不到名為whatsapp_chats.csv的.csv檔案時, createDataset.py才會使用這些檔案。
如果您使用.txt聊天日誌,請注意預期格式是-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(或)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
現在我們所有的對話日誌都是乾淨的格式,我們可以繼續建立我們的資料集。在我們的目錄中,運行:
python createDataset.py然後,系統會提示您輸入您的姓名(以便腳本知道要尋找的人)以及您擁有哪些社群媒體網站的資料。這個腳本將建立一個名為conversationDictionary.npy的文件,它是一個Numpy對象,其中包含(FRIENDS_MESSAGE,YOUR RESPONSE)形式的對。也會建立一個名為conversationData.txt的檔案。這只是一個大文本文件,將字典資料統一為形式。
現在我們有了這 2 個文件,我們可以開始透過 Word2Vec 模型建立詞向量。這一步與其他步驟略有不同。我們稍後看到的 Tensorflow 函數(在 seq2seq.py 中)實際上也處理嵌入部分。因此,您可以決定訓練自己的向量,也可以讓 seq2seq 函數聯合執行,這就是我最終所做的。如果您想透過 Word2Vec 建立自己的詞向量,請在提示符號下輸入 y(執行以下命令後)。如果你不這樣做,那也沒關係,回覆n,這個函數只會建立wordList.txt。
python Word2Vec.py如果完整運行 word2vec.py,這將建立 4 個不同的檔案。 Word2VecXTrain.npy和Word2VecYTrain.npy是 Word2Vec 將使用的訓練矩陣。我們將它們保存在資料夾中,以防我們需要使用不同的超參數再次訓練 Word2Vec 模型。我們也保存wordList.txt ,它只包含我們語料庫中的所有唯一單字。最後儲存的檔案是embeddingMatrix.npy ,它是一個 Numpy 矩陣,包含所有產生的單字向量。
現在,我們可以使用建立和訓練我們的 Seq2Seq 模型。
python Seq2Seq.py這將建立 3 個或更多不同的檔案。 Seq2SeqXTrain.npy和Seq2SeqYTrain.npy是 Seq2Seq 將使用的訓練矩陣。同樣,我們保存這些以防萬一我們想要更改我們的模型架構,並且我們不想重新計算我們的訓練集。最後一個文件將是 .ckpt 文件,其中保存了我們保存的 Seq2Seq 模型。模型將在訓練循環的不同時間段中保存。一旦我們創建了聊天機器人,就會使用和部署這些。
現在我們已經儲存了模型,現在讓我們建立 Facebook 聊天機器人。為此,我建議遵循本教程。您無需閱讀“自訂機器人所說的內容”部分下方的任何內容。我們的 Seq2Seq 模型將處理該部分。重要資訊 - 本教學將告訴您在 Node 專案所在的位置建立一個新資料夾。請記住,此資料夾將與我們的資料夾不同。您可以將此資料夾視為我們的資料預處理和模型訓練所在的位置,而另一個資料夾嚴格保留給Express 應用程式(編輯:我相信您可以按照我們資料夾內的教程步驟操作,只需建立Node 項目,如果需要的話,Procfile 和 index.js 檔案都在此處)。教程本身應該足夠了,但這裡是步驟的摘要。
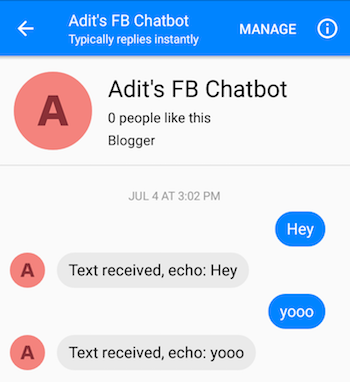
正確執行步驟後,您應該能夠向聊天機器人發送訊息並獲得回應。
啊,你快完成了!現在,我們必須建立一個 Flask 伺服器,可以在其中部署已儲存的 Seq2Seq 模型。我這裡有該伺服器的程式碼。我們來談談整體結構。 Flask 伺服器通常有一個主 .py 文件,您可以在其中定義所有端點。在我們的例子中,這將是 app.py。這將是我們在模型中載入的位置。您應該建立一個名為「models」的資料夾,並在其中填入 4 個檔案(一個檢查點檔案、一個資料檔案、一個索引檔案和一個元檔案)。這些是保存 Tensorflow 模型時所建立的檔案。

在此 app.py 檔案中,我們想要建立一條路線(在我的例子中為 /prediction),其中路線的輸入將輸入到我們儲存的模型中,解碼器輸出是傳回的字串。如果仍然有點令人困惑,請繼續仔細查看 app.py。現在您已經有了 app.py 和模型(以及其他幫助文件,如果需要的話),您可以部署伺服器了。我們將再次使用 Heroku。關於將 Flask 伺服器部署到 Heroku 有很多不同的教程,但我特別喜歡這個(不需要 Foreman 和 Logging 部分)。
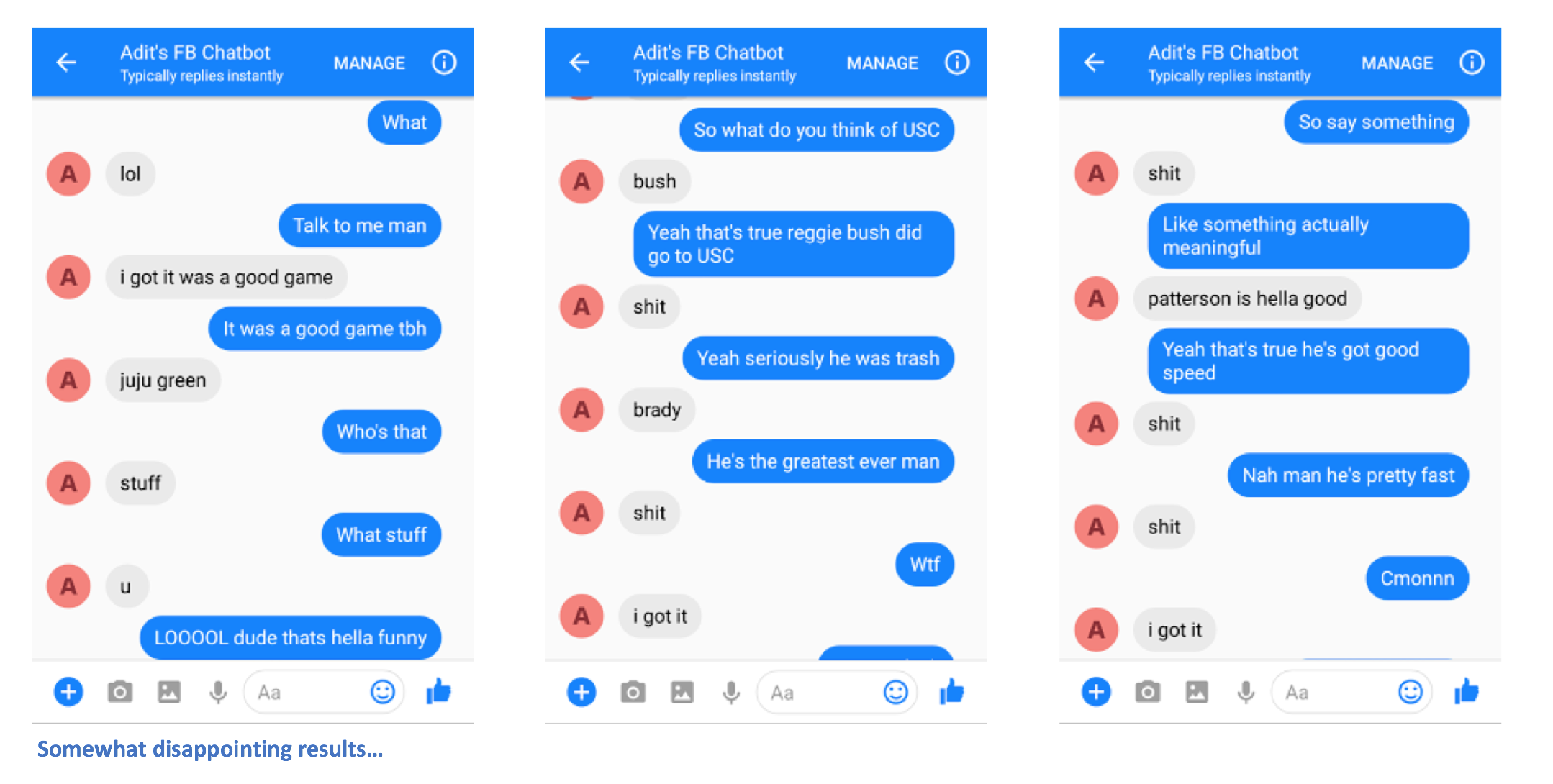
就這樣吧。您應該能夠向聊天機器人發送訊息,並看到一些有趣的回應(希望)在某種程度上與您自己相似。
如果您有任何問題或有任何改進本自述文件的建議,請告訴我。如果您認為某個步驟不清楚,請告訴我,我會盡力編輯自述文件並進行澄清。