Awesome LLM 3D
1.0.0
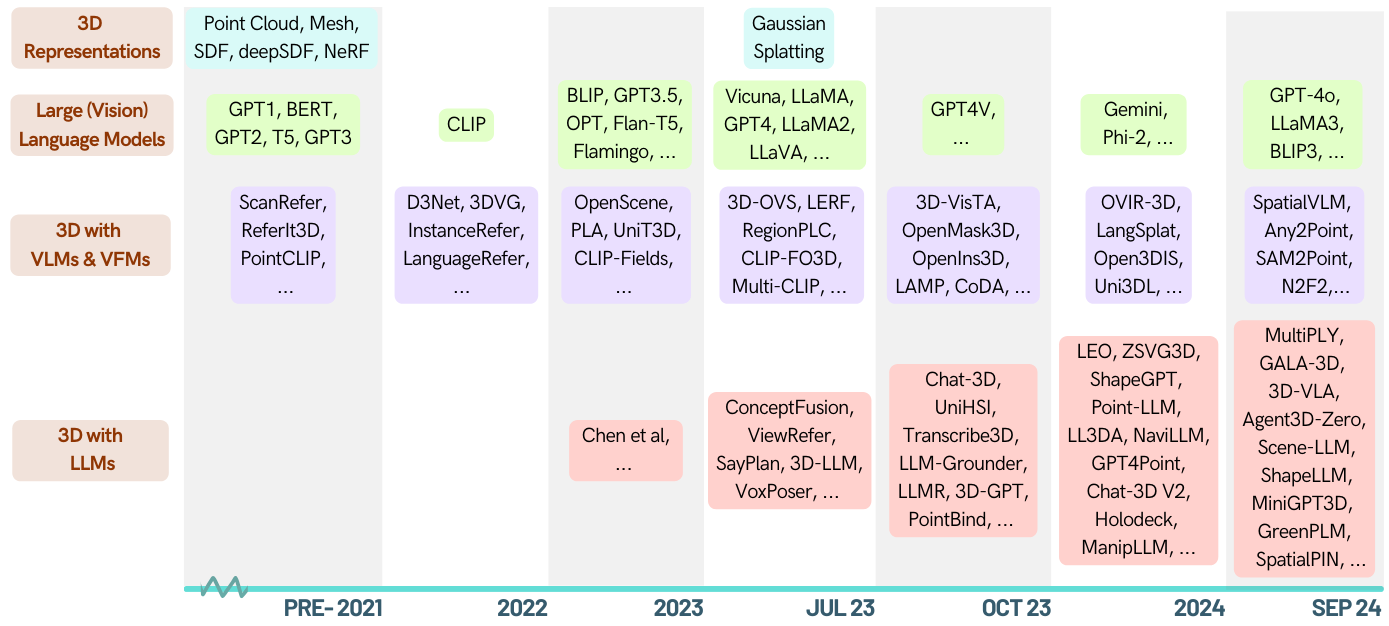
這是關於由大型語言模型(LLM)授權的3D相關任務的策劃列表。它包含各種任務,包括3D理解,推理,生成和具體的代理。此外,我們還包括其他基礎模型(剪輯,SAM),以了解該區域的整個情況。
這是一個活躍的存儲庫,您可以注意遵循最新進展。如果您覺得有用,請友善地將此倉庫播放,並引用紙張。
[2024-05-16]?查看3D-LLM域中的第一張調查文件:當LLMS進入3D世界時:通過多模式大型語言模型對3D任務進行調查和薈萃分析
[2024-01-06] Runsen Xu添加了按時間順序信息,並按照ZA的順序重組了Zianzheng MA,以便在最新進展之後更好地改善它。
[2023-12-16] Xianzheng Ma和Yash Bhalgat策劃了這一列表並發布了第一個版本;
很棒的-LLM-3D
3D理解(LLM)
3D理解(其他基礎模型)
3D推理
3D代
3D體現的代理
3D基準測試
貢獻
| 日期 | 關鍵字 | 研究所(第一) | 紙 | 出版品 | 其他的 |
|---|---|---|---|---|---|
| 2024-10-12 | 情況3d | uiuc | 情境意識在3D視覺語言推理中很重要 | CVPR '24 | 專案 |
| 2024-09-28 | llava-3d | HKU | LLAVA-3D:一種簡單而有效的途徑,可以賦予3D意識的LMM | arxiv | 專案 |
| 2024-09-08 | MSR3D | Bigai | 在3D場景中的多模式位置推理 | Neurips '24 | 專案 |
| 2024-08-28 | Greenplm | 嘿 | 更多文本,更少的要點:邁向3D數據有效的點語言理解 | arxiv | github |
| 2024-06-17 | llana | unibo | Llana:大語和nerf助手 | Neurips '24 | 專案 |
| 2024-06-07 | 空間pin | 牛津 | 空間pin:通過提示和互動3D先驗增強視覺模型的空間推理能力 | Neurips '24 | 專案 |
| 2024-06-03 | 空間rgpt | UCSD | 空間:視覺語言模型中的接地空間推理 | Neurips '24 | github |
| 2024-05-02 | Minigpt-3d | 嘿 | Minigpt-3D:使用2D先驗將3D點雲與大語言模型有效地對齊 | ACM MM '24 | 專案 |
| 2024-02-27 | Shapellm | xjtu | Shapellm:包含相互作用的通用3D對象理解 | arxiv | 專案 |
| 2024-01-22 | ampatialvlm | Google Deepmind | 空間vlm:具有空間推理能力的賦予視覺語言模型 | CVPR '24 | 專案 |
| 2023-12-21 | LIDAR-LLM | PKU | LIDAR-LLM:探索大型語言模型的3D LIDAR理解的潛力 | arxiv | 專案 |
| 2023-12-15 | 3DAP | 上海AI實驗室 | 3DaxiesPrompts:釋放GPT-4V的3D空間任務功能 | arxiv | 專案 |
| 2023-12-13 | 聊天場所 | ZJU | 聊天場景:橋接3D場景和大型語言模型與對象標識符 | Neurips '24 | github |
| 2023-12-5 | GPT4Point | HKU | GPT4Point:一個統一的理解和發電的統一框架 | arxiv | github |
| 2023-11-30 | ll3da | 福丹大學 | LL3DA:視覺互動說明調整,以了解OMNI-3D理解,推理和計劃 | arxiv | github |
| 2023-11-26 | ZSVG3D | Cuhk(SZ) | 零射擊開放式攝影3D視覺接地的視覺編程 | arxiv | 專案 |
| 2023-11-18 | 獅子座 | Bigai | 3D世界中體現的通才代理人 | arxiv | github |
| 2023-10-14 | JM3D-LLM | Xiamen University | JM3D和JM3D-LLM:用聯合多模式提示提升3D表示 | ACM MM '23 | github |
| 2023-10-10 | UNI3D | 拜 | UNI3D:大規模探索統一的3D表示 | ICLR '24 | 專案 |
| 2023-9-27 | - | kaust | 零射3D形狀對應 | Siggraph Asia '23 | - |
| 2023-9-21 | llm-grounder | U-Mich | llm-grounder:用大語言模型作為代理商的開放式vocabulary 3D視覺接地 | ICRA '24 | github |
| 2023-9-1 | 點界 | cuhk | 點綁定和點-LLM:將點雲與多模式的對準點雲,以供3D理解,生成和說明以下 | arxiv | github |
| 2023-8-31 | Pointllm | cuhk | Pointllm:授權大型語言模型以了解點雲 | ECCV '24 | github |
| 2023-8-17 | CHAT-3D | ZJU | CHAT-3D:有效調整3D場景通用對話的大語言模型 | arxiv | github |
| 2023-8-8 | 3D-Vista | Bigai | 3D-Vista:用於3D視覺和文本對齊的預訓練的變壓器 | ICCV '23 | github |
| 2023-7-24 | 3d-llm | 加州大學洛杉磯分校 | 3D-LLM:將3D世界注入大語模型 | Neurips '23 | github |
| 2023-3-29 | ViewRefer | cuhk | ViewRefer:掌握3D視覺接地的多視圖知識 | ICCV '23 | github |
| 2022-9-12 | - | 麻省理工學院 | 利用機器人3D場景理解的大型(視覺)語言模型 | arxiv | github |
| ID | 關鍵字 | 研究所(第一) | 紙 | 出版品 | 其他的 |
|---|---|---|---|---|---|
| 2024-10-12 | 詞典3d | uiuc | 詞典3D:探測複雜3D場景理解的視覺基礎模型 | Neurips '24 | 專案 |
| 2024-10-07 | diff2scene | CMU | 帶有文本對圖像擴散模型的開放式攝煙3D語義分割 | ECCV 2024 | 專案 |
| 2024-04-07 | Any2Point | 上海AI實驗室 | Any2Point:授權任何模式大型模型以進行有效的3D理解 | ECCV 2024 | github |
| 2024-03-16 | N2F2 | 牛津-VGG | N2F2:嵌套神經特徵字段的分層場景理解 | arxiv | - |
| 2023-12-17 | sai3d | PKU | SAI3D:在3D場景中分段任何實例 | arxiv | 專案 |
| 2023-12-17 | Open3dis | Vinai | Open3DIS:帶2D掩碼指南的開放式攝氏3D實例細分 | arxiv | 專案 |
| 2023-11-6 | OVIR-3D | 羅格斯大學 | OVIR-3D:開放式vocabulary 3D實例檢索未經3D數據的培訓 | Corl '23 | github |
| 2023-10-29 | OpenMask3D | eth | OpenMask3D:Open-vocabulary 3D實例分段 | Neurips '23 | 專案 |
| 2023-10-5 | 開放式融合 | - | 開放式融合:實時開放式Vocabulary 3D映射和可查詢場景表示形式 | arxiv | github |
| 2023-9-22 | OV-3DDET | Hkust | CODA:開放式Vocabulary 3D對象檢測的合作小說盒發現和跨模式對齊 | Neurips '23 | github |
| 2023-9-19 | 燈 | - | 從語言到3D世界:適應點雲知覺的語言模型 | OpenReview | - |
| 2023-9-15 | Opennerf | - | Opennerf:開放式套裝3D神經場景細分,具有像素的特徵,並具有新穎的視圖 | OpenReview | github |
| 2023-9-1 | openins3d | 劍橋 | OpenINS3D:3D開放式攝取實例細分的快照和查找 | arxiv | 專案 |
| 2023-6-7 | 對比度提升 | 牛津-VGG | 對比度升降:3D對象實例通過緩慢的對比度融合進行分割 | Neurips '23 | github |
| 2023-6-4 | 多剪輯 | eth | 多卷流:在3D場景中回答任務的對比視力語言預訓練 | arxiv | - |
| 2023-5-23 | 3D-ov | NTU | 弱監督的3D開放式視頻分段 | Neurips '23 | github |
| 2023-5-21 | VL場 | 愛丁堡大學 | VL場:朝著語言基礎的神經隱性空間表示 | ICRA '23 | 專案 |
| 2023-5-8 | 夾子-fo3d | Tsinghua大學 | 剪輯-fo3D:從2D密集剪輯中學習免費的開放世界3D場景表示 | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | eth | 剪輯引導的視覺語言預訓練3D場景中的問答 | CVPRW '23 | github |
| 2023-4-3 | 區域 | HKU | 區域PLC:開放世界3D場景的區域點語言對比學習 | arxiv | 專案 |
| 2023-3-20 | CG3D | jhu | 剪輯進入3D:利用提示調整語言接地的3D識別 | arxiv | github |
| 2023-3-16 | lerf | 加州大學伯克利分校 | LERF:語言嵌入式輻射場 | ICCV '23 | github |
| 2023-2-14 | 概念輸送 | 麻省理工學院 | 概念輸送:開放式多模式3D映射 | RSS '23 | 專案 |
| 2023-1-12 | clip2scene | HKU | 夾子2scene:通過剪輯邁向標籤有效的3D場景 | CVPR '23 | github |
| 2022-12-1 | Unit3d | tum | Unit3D:用於3D密集字幕和視覺接地的統一變壓器 | ICCV '23 | github |
| 2022-11-29 | PLA | HKU | PLA:語言驅動的開放式Vocabulary 3D場景理解 | CVPR '23 | github |
| 2022-11-28 | 開元 | Ethz | 開放式:3D場景與開放的詞彙理解 | CVPR '23 | github |
| 2022-10-11 | 夾場 | 紐約 | 剪輯場:機器人記憶的弱監督語義領域 | arxiv | 專案 |
| 2022-7-23 | 語義抽象 | 哥倫比亞 | 語義抽象:2D視覺模型的開放世界3D場景理解 | Corl '22 | 專案 |
| 2022-4-26 | Scannet200 | tum | 野外語言室內3D語義細分 | ECCV '22 | 專案 |
| 日期 | 關鍵字 | 研究所(第一) | 紙 | 出版品 | 其他的 |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | 加州大學洛杉磯分校 | 從多視圖圖像中的3D概念學習和推理 | CVPR '23 | github |
| - | 轉錄3D | TTI,芝加哥 | Transcribe3D:使用轉錄信息接地LLM,用於3D參考推理,並使用自校正的登錄 | Corl '23 | github |
| 日期 | 關鍵字 | 研究所 | 紙 | 出版品 | 其他的 |
|---|---|---|---|---|---|
| 2023-11-29 | ShapeGpt | 福丹大學 | ShapeGpt:具有統一的多模式模型的3D形狀生成 | arxiv | github |
| 2023-11-27 | meshgpt | tum | Meshgpt:生成三角形網格與僅解碼器的變壓器 | arxiv | 專案 |
| 2023-10-19 | 3D-GPT | 阿努 | 3D-GPT:使用大語言模型的程序3D建模 | arxiv | github |
| 2023-9-21 | llmr | 麻省理工學院 | LLMR:使用大語言模型實時提示交互式世界 | arxiv | - |
| 2023-9-20 | Dreamllm | Megvii | Dreamllm:協同多模式理解和創造 | arxiv | github |
| 2023-4-1 | Chatavatar | Deemos Tech | Dreamface:在文本指導下逐步生成動畫3D面孔 | ACM tog | 網站 |
| 日期 | 關鍵字 | 研究所 | 紙 | 出版品 | 其他的 |
|---|---|---|---|---|---|
| 2024-01-22 | ampatialvlm | 深態 | 空間vlm:具有空間推理能力的賦予視覺語言模型 | CVPR '24 | 專案 |
| 2023-11-27 | dobb-e | 紐約 | 將機器人帶回家 | arxiv | github |
| 2023-11-26 | 史蒂夫 | ZJU | 查看和思考:在虛擬環境中體現的代理 | arxiv | github |
| 2023-11-18 | 獅子座 | Bigai | 3D世界中體現的通才代理人 | arxiv | github |
| 2023-9-14 | Unihsi | 上海AI實驗室 | 統一的人類習慣通過促進的接觸鏈互動 | arxiv | github |
| 2023-7-28 | RT-2 | Google-Deepmind | RT-2:視覺語言動作模型將Web知識轉移到機器人控制 | arxiv | github |
| 2023-7-12 | Sayplan | QUT機器人中心 | SAIDPLAN:使用3D場景圖進行擴展機器人任務計劃的大型語言模型 | Corl '23 | github |
| 2023-7-12 | voxposer | 斯坦福大學 | Voxposer:使用語言模型的機器人操作的可組合3D值圖 | arxiv | github |
| 2022-12-13 | RT-1 | RT-1:用於實際控制的機器人變壓器 | arxiv | github | |
| 2022-12-8 | LLM-Planner | 俄亥俄州立大學 | LLM-Planner:具有大語言模型的具體代理的基礎計劃很少 | ICCV '23 | github |
| 2022-10-11 | 夾場 | 紐約州,元 | 剪輯場:機器人記憶的弱監督語義領域 | RSS '23 | github |
| 2022-09-20 | nlmap-saycan | 現實世界規劃的開放式唱歌可查詢場景表示 | ICRA '23 | github |
| 日期 | 關鍵字 | 研究所 | 紙 | 出版品 | 其他的 |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | Bigai | 在3D場景中的多模式位置推理 | Neurips '24 | 專案 |
| 2024-06-10 | 3D-Grand / 3D-Pope | 烏米 | 3D grand:3D-llms的一百萬尺度數據集,其接地更好,幻覺更少 | arxiv | 專案 |
| 2024-06-03 | 時髦台式板凳 | UCSD | 空間:視覺語言模型中的接地空間推理 | Neurips '24 | github |
| 2024-1-18 | 場景 | Bigai | 場景:縮放3D視覺學習,用於接地場景理解 | arxiv | github |
| 2023-12-26 | 體現 | 上海AI實驗室 | 體現:整體多模式3D感知套件朝著體現的AI | arxiv | github |
| 2023-12-17 | M3dbench | 福丹大學 | M3DBENCH:讓我們指導具有多模式3D提示的大型型號 | arxiv | github |
| 2023-11-29 | - | 深態 | 評估3D對象的基於得分的多探針註釋的VLM | arxiv | github |
| 2023-09-14 | 交叉協調 | unibo | 關注文字和點:文本對形狀相干性的基準 | ICCV '23 | github |
| 2022-10-14 | SQA3D | Bigai | SQA3D:位於3D場景中的問題 | ICLR '23 | github |
| 2021-12-20 | Scanqa | Riken AIP | Scanqa:3D問題回答空間場景的理解 | CVPR '23 | github |
| 2020-12-3 | scan2cap | tum | Scan2CAP:RGB-D掃描中的上下文感知的密集字幕 | CVPR '21 | github |
| 2020-8-23 | Referit3d | 斯坦福大學 | 推薦3D:現實場景中細粒3D對象識別的神經聽眾 | ECCV '20 | github |
| 2019-12-18 | 掃描 | tum | 掃描:3D對像在RGB-D中使用自然語言進行定位 | ECCV '20 | github |
您的貢獻始終歡迎!
如果我不確定它們是否對3D LLM很棒,您可以通過添加來投票給它們,我會保持一些拉動請求嗎?給他們。
如果您對此有任何疑問,請通過[email protected]或微信ID與MXZ1997112聯繫。
如果您發現此存儲庫有用,請考慮引用本文:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}此存儲庫的靈感來自很棒


