IncarnaMind
1.0.0
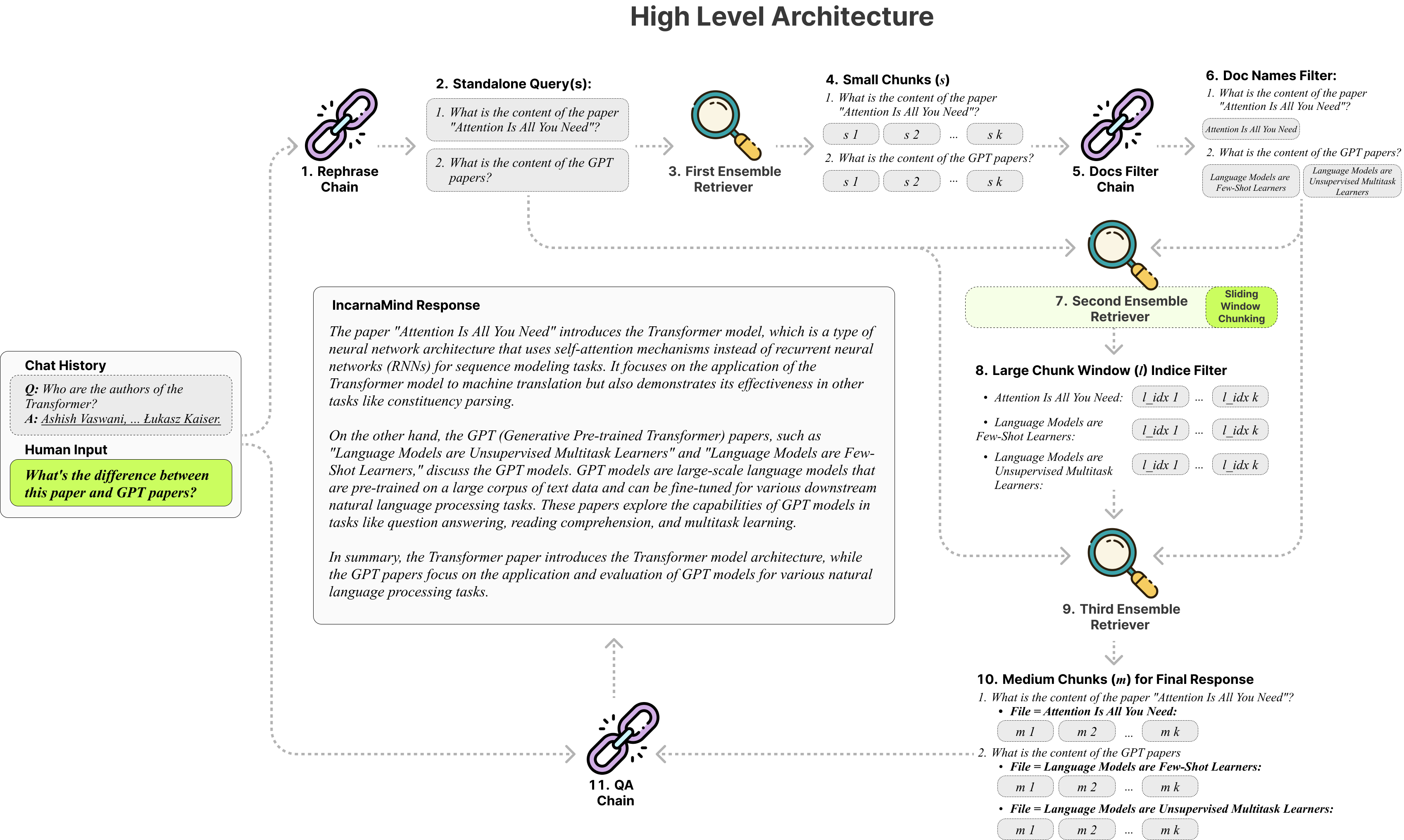
Uncarnamind使您可以與您的個人文件聊天? (PDF,TXT)使用大型語言模型(LLM)(例如GPT)(架構概述)。雖然OpenAI最近推出了用於GPT模型的微調API,但它並不能使基本概括的模型能夠學習新數據,並且響應可能容易出現事實幻覺。利用我們的滑動窗口塊機制和集合回收刀可以在地面真相文檔中有效查詢細粒度和粗粒的信息,以增強LLMS。
隨時使用它,我們歡迎任何反饋和新功能建議嗎?
這是我測試過的不同模型的比較表,僅參考:
| 指標 | GPT-4 | GPT-3.5 | 克勞德2.0 | Llama2-70B | LLAMA2-70B-GGUF | Llama2-70b-api |
|---|---|---|---|---|---|---|
| 推理 | 高的 | 中等的 | 高的 | 中等的 | 中等的 | 中等的 |
| 速度 | 中等的 | 高的 | 中等的 | 非常低 | 低的 | 中等的 |
| GPU RAM | N/A。 | N/A。 | N/A。 | 很高 | 高的 | N/A。 |
| 安全 | 低的 | 低的 | 低的 | 高的 | 高的 | 低的 |
固定塊:傳統的抹布工具依靠固定的塊大小,從而將其適應性限制在處理不同的數據複雜性和上下文中。
精度與語義:當前的檢索方法通常集中於語義理解或精確檢索,但很少兩者兼而有之。
單案限制:許多解決方案一次只能一次查詢一個文檔,從而限制多文件信息檢索。
穩定性:Incarnamind與Openai GPT,人類Claude,Llama2和其他開源LLM兼容,可確保穩定的解析。
自適應塊:我們的滑動窗口塊技術可以動態調整窗口的大小和位置,以基於數據複雜性和上下文平衡細粒度和粗粒的數據訪問。
多文件對話質量質量檢查:同時支持多個文檔跨多個文檔的簡單和多跳的查詢,從而打破了單文件限制。
文件兼容性:支持PDF和TXT文件格式。
LLM模型兼容性:支持OpenAI GPT,人類Claude,Llama2和其他開源LLM。

安裝很簡單,您只需要運行幾個命令即可。
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMind創建conda虛擬環境:
conda create -n IncarnaMind python=3.10啟用設定:
conda activate IncarnaMind安裝所有要求:
pip install -r requirements.txt如果您想運行量化的本地LLM,請安裝Llama-CPP。
NVIDIA GPU支持,請使用cuBLAS CMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 )支持,請使用CMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dir在configparser.ini文件中設置您的一個/所有API鍵:
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(可選)在configparser.ini文件中設置自定義參數:
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)將所有文件(請正確命名每個文件以最大化性能命名)中的/數據目錄,然後運行以下命令攝入所有數據:(您可以在運行命令之前刪除/數據目錄中的示例文件)
python docs2db.py為了開始對話,請運行一個命令:
python main.py等待腳本需要下面的輸入。
Human:啟動聊天時,系統將自動生成一個incarnamind.log文件。如果要編輯日誌記錄,請在configparser.ini文件中進行編輯。
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)s特別感謝Langchain,Chroma DB,Lastgpt,Llama-CPP對開源社區的寶貴貢獻。他們的作品在使孟買項目成為現實方面發揮了作用。
如果您想引用我們的工作,請使用以下Bibtex條目:
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Apache 2.0許可證


