我們在上一節爬取了網頁的全部信息,下面我們還要這樣html程式碼中找到我們所需要的內容,因此我們要根據問題進入網站中,去解析網頁中的信息。
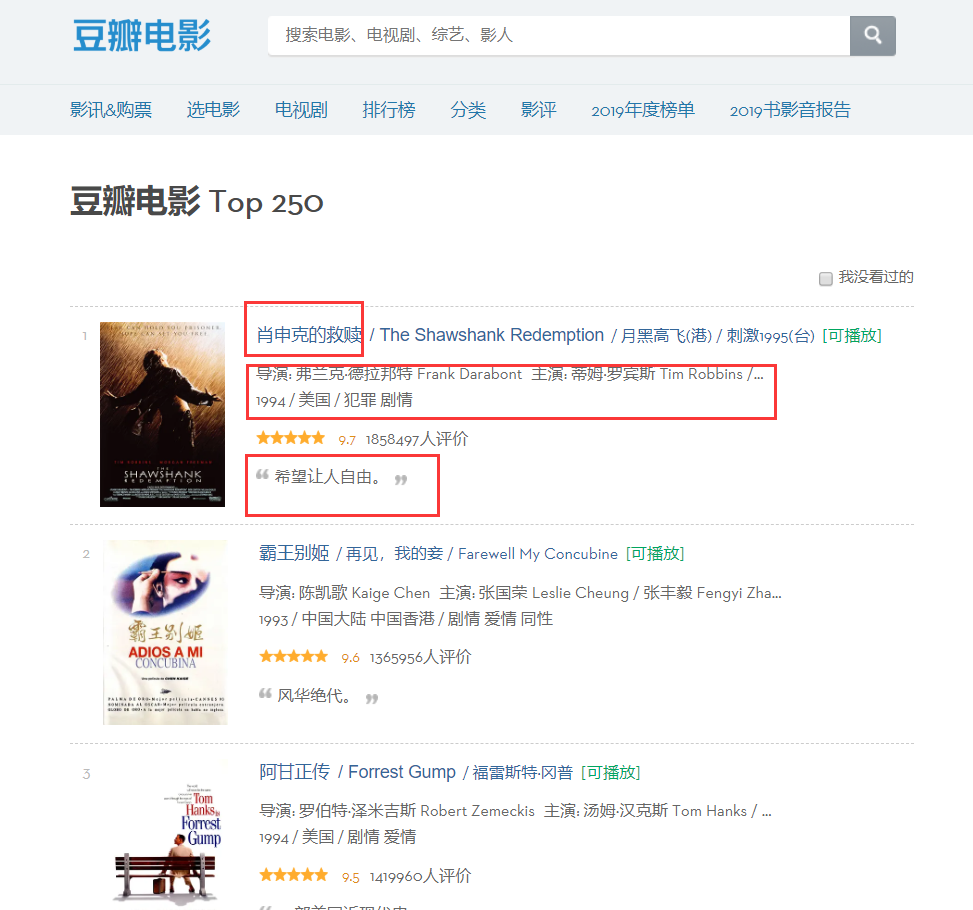
從頁面中可以發現,我們需要爬取的資訊分別存在於不同的分區當中,那麼我們來檢查頁面的元素,右鍵頁面檢查網頁原始碼或F12。

在分析網頁之前,我們先規定一下解析之後的儲存方式,這裡我們採用列表來儲存所有的信息,然後列表中的每一項對應一個字典,每一個字典再對應多種資訊。
movies=[]#先定義一個列表來儲存所有資訊
透過分析我們可以確定title的位置是名為'hd'的'div'下的第一個'a'中的第一個'span',因此我們可以透過下面代碼來鎖定每一部電影的名字,然後放到一個字典。
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#字典的一項相同的方式可以再根據定位找到導演名的源碼,但是這個源碼中包含了很多信息,所以我們要通過正則表達式進行過濾。
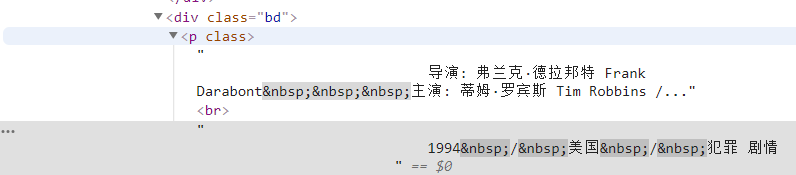
info=each.find('div',class_='bd').p.text.strip()首先找到了這個標籤下的所有內容,我們再透過正規表示式過濾掉無關資訊。
info=info.replace('n',)#過濾回車info=info.replace(,)#過濾空格info=info.replace(xa0,)#過濾不間斷空白空白符號director=re.findall(r '[導演:].+[主演:]',info)[0]director=director[3:len(director)-6]然後定義為字典的一項。
movie['director']=director#字典的一項
我們可以發現電影類型也在這個'p'標籤中,我們也直接透過正規表示式來獲取該資訊。
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#加入為字典的一項最後再鎖定評分資訊。
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()然後繼續以字典的形式保存。
movie['star']=star
最後把這個字典加到列表中並遍歷輸出。
movies.append(movie)#把字典加到列表中foriinmovies:#遍歷輸出print(i)
。 ,'Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25次r=requests.get(res,headers =headers,timeout=10)#設定逾時時間soup=BeautifulSoup(r.text,html.parser)#設定解析方式,也可以使用其他方式。 div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[導演:].+[主演:]',info)[0]director=director[3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]movie['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0] plot=plot[1:]plot=plot[plot.index('/')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each. find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (i)控制台:

在這個實例中,我們主要學習如何去網頁的源碼中找到相應的信息,BeautifulSoup可以幫助我們迅速定位,再結合正則表達式來完成信息的匹配,下一節我們把這些數據保存到數據庫當中。