Salesforce AI 研究團隊最新發布的多模態語言模型BLIP-3-Video,為高效處理日益增長的視訊資料提供了解決方案。此模型旨在提升影片理解效率和效果,廣泛應用於自動駕駛、娛樂等領域,為各行各業帶來革新。 Downcodes小編將為您詳細解讀BLIP-3-Video 的核心技術與卓越效能。
最近,Salesforce AI 研究團隊推出了全新的多模態語言模式—BLIP-3-Video。隨著影片內容的快速增加,如何有效處理影片資料成為了一個亟待解決的問題。這款模型的出現,旨在提升影片理解的效率和效果,適用於從自動駕駛到娛樂等各個產業。
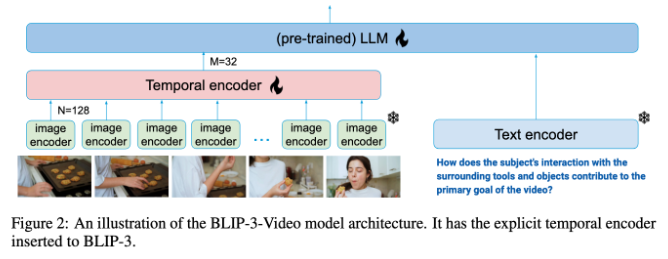
傳統的視頻理解模型往往是逐幀處理視頻,產生大量的視覺訊息。這個過程不僅消耗了大量的運算資源,也大大限制了處理長影片的能力。隨著視訊資料量的不斷增長,這種方法變得愈發低效,因此,找到一種既能捕捉到視訊的關鍵訊息,又能減少計算負擔的解決方案至關重要。
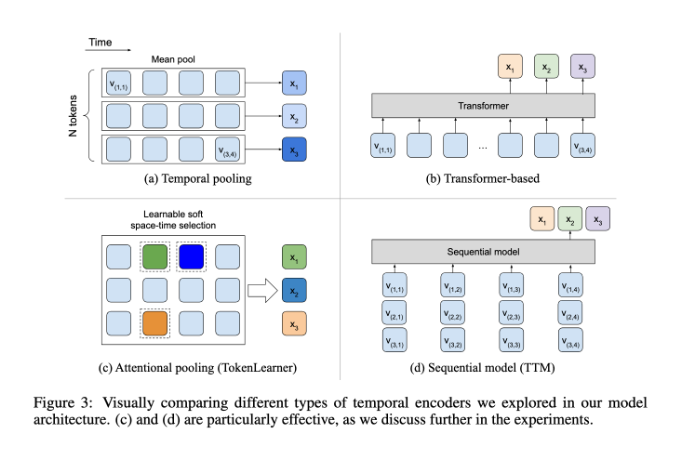
在這方面,BLIP-3-Video 表現得相當出色。該模型透過引入“時序編碼器”,成功將影片中所需的視覺訊息數量減少到16到32個視覺標記。這項創新設計大大提高了運算效率,讓模型能夠以更低的成本完成複雜的視訊任務。這個時序編碼器採用了一種可學習的時空注意力池化機制,能夠從每一幀中提取最重要的訊息,將其整合成一個緊湊的視覺標記集。
BLIP-3-Video 的表現也非常出色。透過與其他大型模型的比較,研究發現,該模型在視訊問答任務中的準確率與頂尖模型相當。例如,Tarsier-34B 模型處理8幀視訊需要4608個標記,而BLIP-3-Video 只需32個標記,就能實現77.7% 的MSVD-QA 基準得分。這顯示出BLIP-3-Video 在維持高效能的同時,顯著減少了資源消耗。
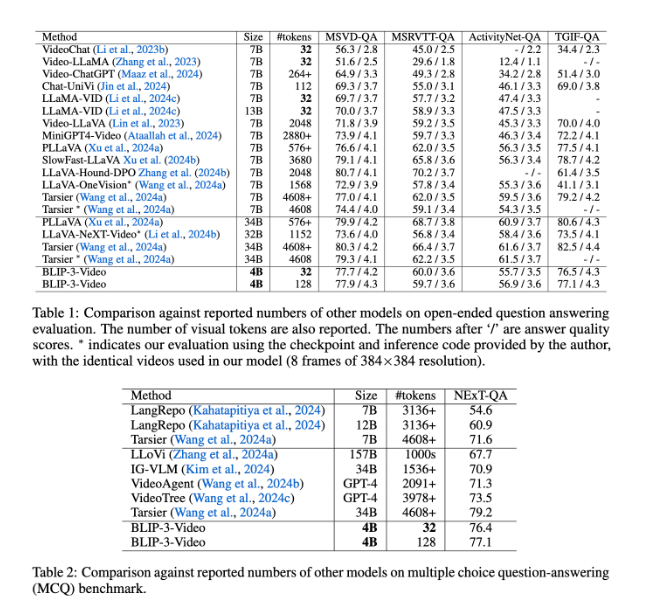
此外,BLIP-3-Video 在多項選擇問答任務中的表現同樣不容小覷。在NExT-QA 資料集中,模型取得了77.1% 的高分,而在TGIF-QA 資料集中,也達到了77.1% 的準確率。這些數據都表明,BLIP-3-Video 在處理複雜視訊問題時的高效性。

BLIP-3-Video 透過創新的時序編碼器,在視訊處理領域開闢了新的可能性。這款模型的推出,不僅提升了影片理解的效率,也為未來的影片應用提供了更多可能性。
專案入口:https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
BLIP-3-Video憑藉其高效的視訊處理能力,為未來視訊技術發展提供了新的方向。其在視訊問答和多項選擇問答任務中的出色表現,證明了其在資源節約和性能提升方面的巨大潛力。 期待BLIP-3-Video在更多領域發揮作用,推動視訊技術的進步。