Downcodes小編帶你解讀普林斯頓大學和耶魯大學最新研究成果!研究深入探討了大語言模型(LLM)的「思維鏈(CoT)」推理能力,揭示了CoT推理並非簡單的邏輯規則應用,而是記憶、機率和噪音推理等多種因素的複雜融合。研究人員選取了移位密碼破解任務,對GPT-4、Claude3和Llama3.1這三個LLM進行了深入分析,最終發現了影響CoT推理效果的三個關鍵因素,並對LLM的推理機制提出了新的見解。
普林斯頓大學和耶魯大學的研究人員最近發布了一份關於大語言模型(LLM)「思維鏈(CoT)」推理能力的報告,揭示了CoT推理的奧秘:它並非純粹基於邏輯規則的符號推理,而是融合了記憶、機率和噪音推理等多種因素。
研究人員以破解移位密碼為測試任務,分析了GPT-4、Claude3和Llama3.1這三個LLM的表現。移位密碼是一種簡單的編碼方式,每個字母都被替換成字母表中向前移動固定位數的字母。例如,將字母表向前移動3位,CAT就會變成FDW。
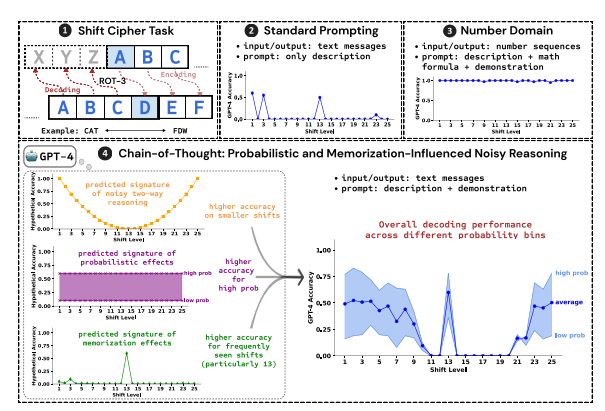
研究結果表明,影響CoT推理效果的三個關鍵因素是:
機率:LLM更傾向於產生機率較高的輸出,即使推理步驟指向的是機率較低的答案。例如,如果推理步驟指向STAZ,但STAY是更常見的單詞,LLM可能會「自我修正」並輸出STAY。
記憶:LLM在預訓練過程中記住了大量文本數據,這會影響其CoT推理的準確性。例如,rot-13是最常見的移位密碼,LLM在rot-13上的準確率明顯高於其他類型的移位密碼。
噪音推理:LLM的推理過程並非完全準確,而是存在一定程度的噪音。隨著移位密碼的位移量增加,解碼所需的中間步驟也隨之增加,雜訊推理的影響也更加明顯,導致LLM的準確率下降。
研究人員還發現,LLM的CoT推理依賴於自我條件化,即LLM需要明確生成文本作為後續推理步驟的脈絡。如果LLM被指示「默默思考」而不輸出任何文本,其推理能力就會大幅下降。 此外,演示步驟的有效性對CoT推理的影響並不大,即使演示步驟有錯誤,LLM的CoT推理效果仍可維持穩定。
這項研究表明,LLM的CoT推理並非完美的符號推理,而是融合了記憶、機率和噪音推理等多種因素。 LLM在CoT推理過程中既表現出記憶大師的特點,也展現了機率高手的風範。這項研究有助於我們更深入地理解LLM的推理能力,並為未來開發更強大的AI系統提供valuable insights。
論文網址:https://arxiv.org/pdf/2407.01687
這篇研究報告為我們理解大語言模型的「思考鏈」推理機制提供了寶貴的參考,也為未來AI系統的設計與最佳化提供了新的方向。 Downcodes小編將持續關注人工智慧領域的前沿進展,為大家帶來更多精彩內容!