Downcodes小編獲悉,中國研究團隊成功創建了目前最大規模的公開多模態AI資料集“Infinity-MM”,並基於此資料集訓練出性能卓越的小型模型Aquila-VL-2B。此模型在多個基準測試中取得優異成績,展現了合成數據在提升AI模型效能方面的巨大潛力。 Infinity-MM資料集包含影像描述、視覺指令資料等多種類型數據,其生成過程利用了RAM++和MiniCPM-V等開源AI模型,並經過多層次處理以確保資料品質和多樣性。 Aquila-VL-2B模型則以LLaVA-OneVision架構,並以Qwen-2.5作為語言模型。
近日,來自多家中國機構的研究團隊成功創建了「Infinity-MM」 資料集,這是目前最大規模的公開多模態AI 資料集之一,同時訓練出了一款性能卓越的小型新模型— —Aquila-VL-2B。
該資料集主要包含四大類數據:1000萬條圖像描述、2440萬條一般視覺指令數據、600萬條精選高品質指令數據,以及300萬條由GPT-4和其他AI 模型生成的數據。
在生成方面,研究團隊利用現有的開源AI 模型。首先,RAM++ 模型分析影像並提取重要訊息,隨後產生相關問題和答案。此外,團隊還建立了一種特殊的分類系統,確保產生數據的品質和多樣性。
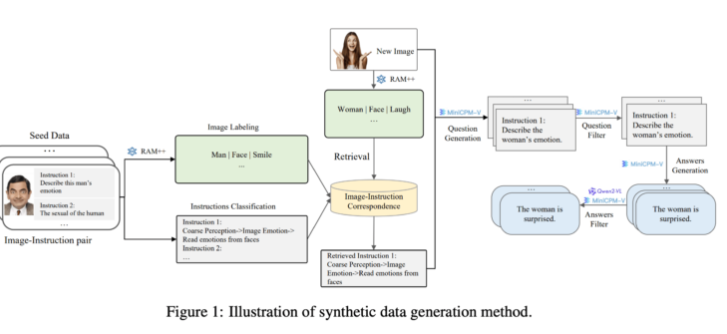
此合成資料生成方法採用了多層次的處理方式,結合了RAM++ 和MiniCPM-V 模型,透過影像辨識、指令分類和回應生成,為AI 系統提供了精準的訓練資料。
Aquila-VL-2B 模型基於LLaVA-OneVision 架構,使用Qwen-2.5作為語言模型,並採用SigLIP 進行影像處理。模型的訓練分為四個階段,逐步提升複雜性。在第一階段,模型學習了基本的圖像- 文字關聯;後續階段則包含一般視覺任務、具體指令的執行,以及最終整合合成生成的資料。的影像解析度也在訓練逐漸提升。
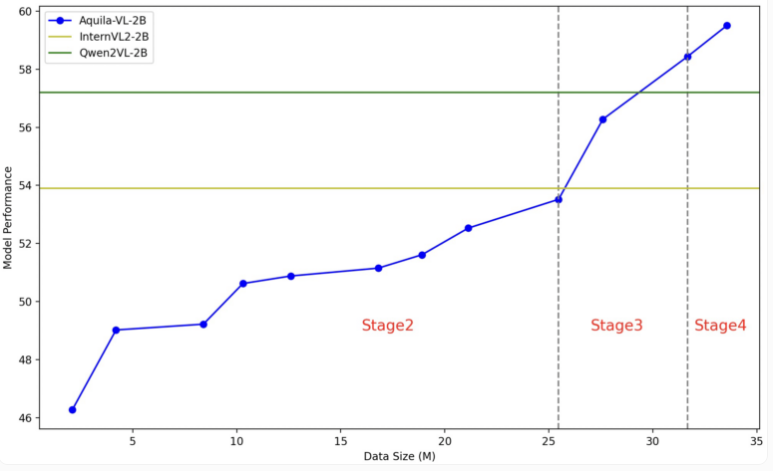
測試中,Aquila-VL-2B 憑藉僅20億參數的體積,在多模態的MMStar 基測中以54.9% 的得分下最佳成績。此外,在數學任務中,模型表現特別突出,在MathVista 測驗中得分達59%,遠超同類系統。
在通用影像理解的測驗中,Aquila-VL-2B 同樣表現優異,HallusionBench 得分為43%,MMBench 得分為75.2%。研究人員表示,合成生成數據的加入顯著提升了模型的表現,若不使用這些額外數據,模型的平均表現將下降2.4%。
此次研究團隊決定將資料集和模型向研究社群開放,訓練過程主要使用Nvidia A100GPU 及中國本土晶片。 Aquila-VL-2B 的成功推出,標誌著開放原始碼模型在AI 研究中逐漸迎頭趕上傳統閉源系統的趨勢,尤其是在利用合成訓練資料方面展現出良好的前景。
Infinity-MM論文入口:https://arxiv.org/abs/2410.18558
Aquila-VL-2B計畫入口:https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Aquila-VL-2B的成功,不僅證明了中國在AI領域的技術實力,也為開源社群提供了寶貴的資源。其高效的性能和開放的策略,將推動多模態AI技術的發展,值得期待其未來在更多領域的應用。