大模型訓練耗時耗力,如何提升效率降低能耗成為AI領域的關鍵問題。 AdamW作為Transformer預訓練的預設優化器,在面對日益龐大的模型時也逐漸力不從心。 Downcodes小編帶您了解一個由華人團隊開發的全新優化器——C-AdamW,它以其「謹慎」的策略,在確保訓練速度和穩定性的同時,大幅降低能耗,為大模型訓練帶來革命性改變。
在AI 的世界裡,大力出神蹟似乎成了金科玉律。模型越大,資料越多,算力越強,彷彿就能越接近智慧的聖杯。然而,這狂飆突進的背後,也隱藏著龐大的成本和能耗壓力。
為了讓AI 訓練更有效率,科學家一直在尋找更強大的優化器,就像一位教練,引導模型的參數不斷優化,最終達到最佳狀態。 AdamW 作為Transformer 預訓練的預設優化器,多年來一直是業界標竿。然而,面對日益龐大的模型規模,AdamW 也開始顯得力不從心。
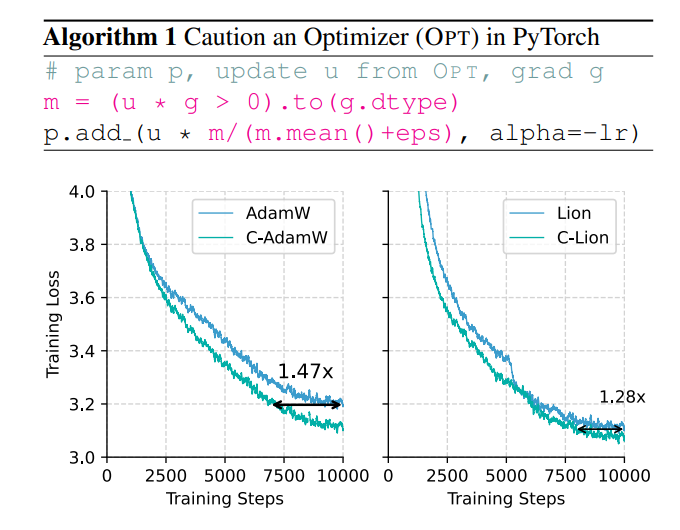
難道就沒有一種方法,既能提升訓練速度,又能降低能耗嗎?別急,一個全華人團隊帶著他們的秘密武器C-AdamW 來啦!
C-AdamW 全名為Cautious AdamW,中文名謹慎AdamW,是不是聽起來就很佛系?沒錯,C-AdamW 的核心思想就是三思而後行。

想像一下,模型的參數就像一群精力旺盛的小朋友,總想四處亂跑。 AdamW 就像一位盡職盡責的老師,努力引導他們朝著正確的方向前進。但有時候,小朋友會太興奮,跑錯了方向,反而浪費了時間和精力。
這時候,C-AdamW 就像是個智慧的長者,戴著一副火眼金睛,能夠精準辨識更新方向是否正確。如果方向錯了,C-AdamW 就會果斷喊停,避免模型在錯誤的道路上越走越遠。
這種謹慎的策略,保證了每次更新都能有效地降低損失函數,從而加快模型的收斂速度。實驗結果表明,C-AdamW 在Llama 和MAE 預訓練中,將訓練速度提升至1.47倍!
更重要的是,C-AdamW 幾乎沒有額外的計算開銷,只需對現有程式碼進行一行簡單的修改即可實現。這意味著,開發者可以輕鬆地將C-AdamW 應用到各種模型訓練中,享受速度與激情!
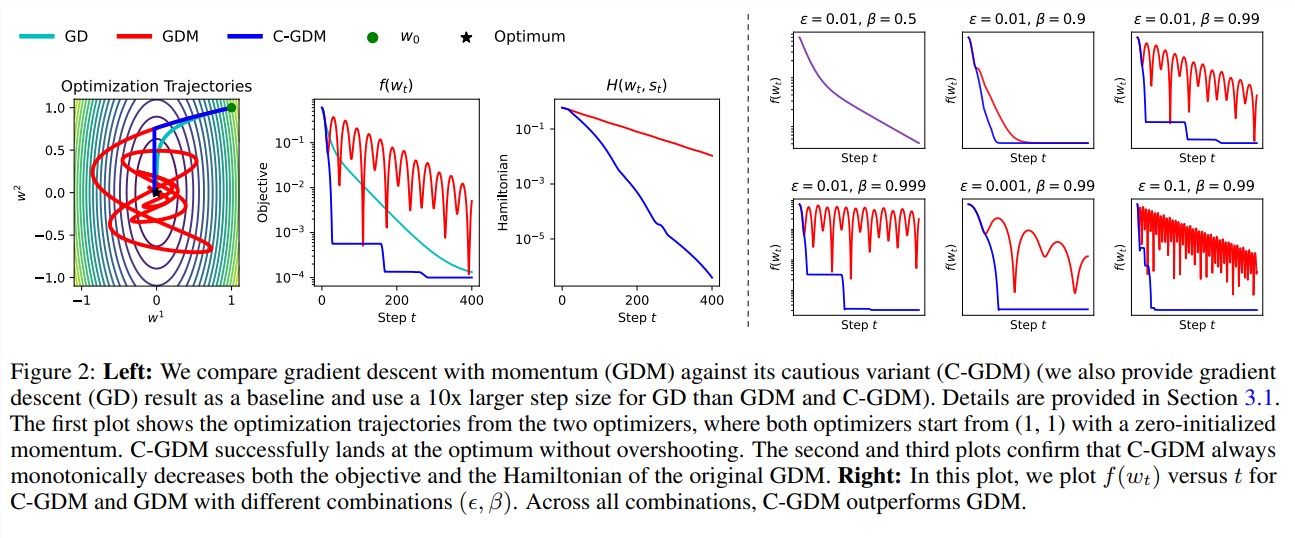
C-AdamW 的佛系之處,還在於它保留了Adam 的哈密頓函數,並在李雅普諾夫分析下不破壞收斂性保證。這意味著,C-AdamW 不僅速度更快,而且穩定性也得到了保障,不會出現訓練崩潰等問題。
當然,佛係不代表不思進取。研究團隊表示,他們將繼續探索更豐富的ϕ 函數,並在特徵空間而非參數空間中應用掩碼,以進一步提升C-AdamW 的性能。
可以預見,C-AdamW 將成為深度學習領域的新寵,為大模型訓練帶來革命性的改變!
論文網址:https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
C-AdamW 的出現為解決大模型訓練效率和能耗問題提供了新的思路,其高效、穩定以及易於使用的特性使其極具應用前景。期待未來C-AdamW能在更多領域得到應用,推動AI技術持續發展。 Downcodes小編將持續關注相關技術進展,敬請期待!