Downcodes小編獲悉,北京大學等科研團隊重磅發表LLaVA-o1,一款具有里程碑意義的多模態開源模型。該模型在多個基準測試中超越了Gemini、GPT-4o-mini和Llama等競爭對手,其「慢思考」推理機制使其能夠進行更複雜的推理,堪比GPT-o1。 LLaVA-o1的開源,將為多模態AI領域的研究和應用帶來新的活力。
近日,北京大學等科研團隊宣布發布了一款名為LLaVA-o1的多模態開源模型,據稱這是第一個能夠進行自發、系統推理的視覺語言模型,堪比GPT-o1。
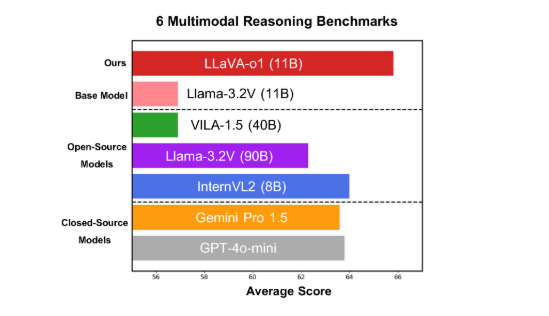
該模型在六個具有挑戰性的多模態基準測試中表現優異,其11B 參數的版本超越了其他競爭者,如Gemini-1.5-pro、GPT-4o-mini 和Llama-3.2-90B-Vision- Instruct。
LLaVA-o1基於Llama-3.2-Vision 模型,採用了「慢思考」 推理機制,能夠自主進行更複雜的推理過程,超越了傳統的思維鏈提示方法。
在多模態推理基準測試中,LLaVA-o1的表現超越了其基礎模型8.9%。此模型的獨特之處在於其推理過程被分為四個階段:總結、視覺解釋、邏輯推理和結論生成。在傳統模型中,推理過程往往比較簡單,容易導致錯誤答案,而LLaVA-o1透過結構化的多步驟推理,確保了更精準的輸出。
例如,在解決「減去所有的小亮球和紫色物體,剩下多少個物體?」 的問題時,LLaVA-o1會首先總結問題,接著從圖像中提取信息,然後進行逐步推理,最終給出答案。這種分階段的方法提升了模型的系統推理能力,使其在處理複雜問題時更有效率。

值得一提的是,LLaVA-o1在推理過程中引入了階段級光束搜尋方法。這種方法允許模型在每個推理階段產生多個候選答案,並選擇最佳的答案繼續進行下一階段的推理,從而顯著提高了整體推理品質。透過監督微調和合理的訓練數據,LLaVA-o1在與更大或閉源模型的比較中表現出色。
北大團隊的研究成果不僅推動了多模態AI 的發展,也為未來的視覺語言理解模式提供了新的思路和方法。團隊表示,LLaVA-o1的程式碼、預訓練權重和資料集都將全面開源,期待更多研究者和開發者能夠共同探索和應用這項創新模型。
論文:https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
LLaVA-o1的開源,無疑將促進多模態AI領域的技術發展和應用創新。其高效的推理機制和優秀的性能,使其成為未來視覺語言模型研究的重要參考,值得關注和期待。期待更多開發者參與其中,共同推動人工智慧技術進步。