你是否對ChatGPT、文心一言等AI產品背後的技術感到好奇?它們都依賴大型語言模型(LLM)。 Downcodes小編將以簡單易懂的方式,帶你了解LLM的運作原理,即使你只有小學二年級的數學程度也能輕鬆理解!我們將從神經網路的基本概念出發,逐步解說模型訓練、進階技巧以及GPT和Transformer架構等核心技術,讓你對LLM有一個清晰的認知。
聽過ChatGPT、文心一言這些高大上的AI嗎?它們背後的核心技術就是「大型語言模型」(LLM)。是不是覺得很複雜,很難理解?別擔心,即使你只有小學二年級的數學水平,看完這篇文章,也能輕鬆掌握LLM的運作原理!
神經網路:數字的魔法
首先,我們要知道,神經網路就像一個超級計算器,它只能處理數字。無論是輸入還是輸出,都必須是數字。那我們要怎麼讓它理解文字呢?
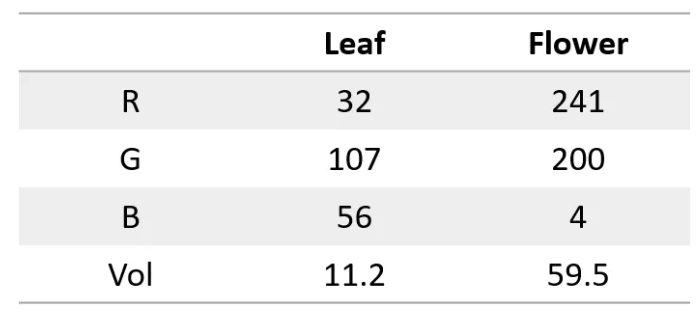
秘訣就在於把文字轉換成數字! 例如,我們可以把每個字母用一個數字代表,例如a=1,b=2,以此類推。這樣一來,神經網路就能「讀懂」文字了。
訓練模型:讓網路「學會」語言
有了數位化的文字,接下來就要訓練模型,讓神經網路「學會」語言的規律。
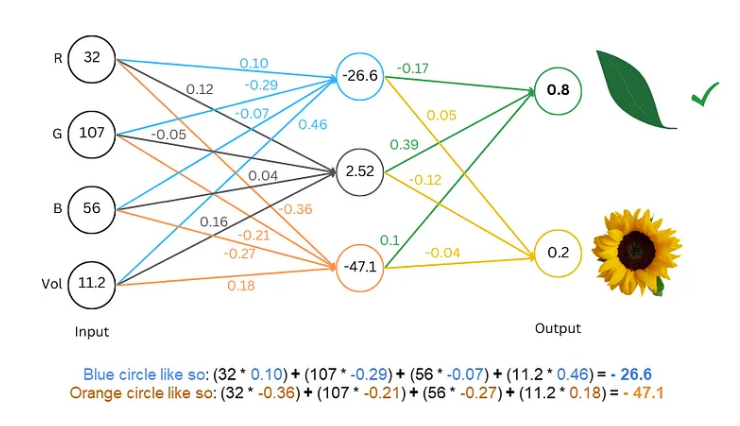
訓練的過程就像玩猜謎遊戲。 我們給網路看一些文字,像是“Humpty Dumpty”,然後讓它猜下一個字母是什麼。如果它猜對了,我們就給它獎勵;如果猜錯了,就給它懲罰。透過不斷地猜謎和調整,網路就能越來越準確地預測下一個字母,最終產生完整的句子,例如「Humpty Dumpty sat on a wall」。
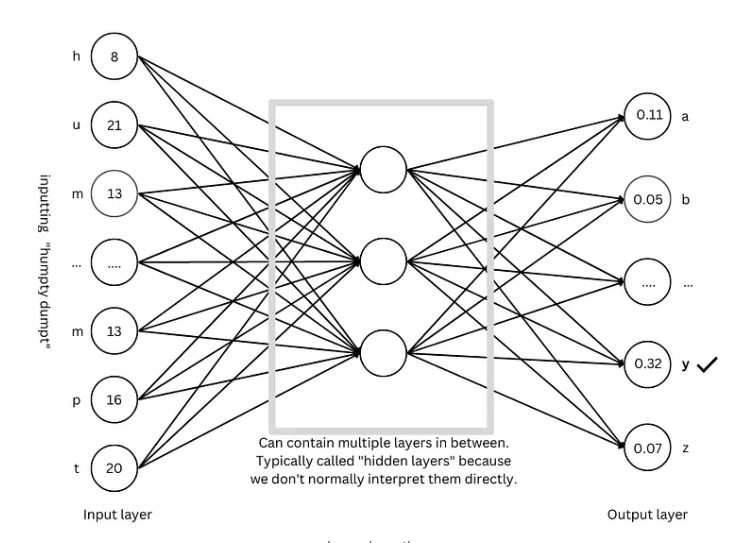
進階技巧:讓模型更“聰明”
為了讓模型更“聰明”,研究人員發明了許多進階技巧,例如:
詞嵌入: 我們不再用簡單的數字代表字母,而是用一組數字(向量)來代表每個詞,這樣可以更全面地描述詞語的含義。
子詞分詞器: 把單字拆分成更小的單位(子詞),例如把“cats”拆成“cat”和“s”,這樣可以減少詞彙量,提高效率。
自註意力機制: 模型在預測下一個詞時,會根據上下文中的所有詞語來調整預測的權重,就像我們在閱讀時會根據上下文理解詞義一樣。
殘差連接: 為了避免網路層數過多導致訓練困難,研究人員發明了殘差連接,讓網路更容易學習。
多頭注意力機制: 透過並行運行多個注意力機制,模型可以從不同的角度理解上下文,提高預測的準確性。
位置編碼: 為了讓模型理解詞語的順序,研究者會在詞嵌入中加入位置訊息,就像我們在閱讀時會注意詞語的順序一樣。
GPT 架構:大型語言模型的“藍圖”
GPT 架構是目前最受歡迎的大型語言模型架構之一,它就像一個“藍圖”,指引著模型的設計和訓練。 GPT 架構巧妙地組合了上述的各種進階技巧,讓模型能夠有效率地學習和生成語言。
Transformer 架構:語言模型的“革命”
Transformer 架構是近年來語言模型領域的一項重大突破,它不僅提高了預測的準確性,還降低了訓練的難度,為大型語言模型的發展奠定了基礎。 GPT 架構也是基於Transformer 架構演進而來的。
參考資料:https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
希望Downcodes小編的講解能幫助你理解大型語言模型的運作原理。 當然,LLM 的技術還在不斷發展,這篇文章只是冰山一角, 更多更深入的內容還需要你持續學習和探索!