Downcodes小編獲悉,Meta近日發布了全新的多語言多輪對話指令遵循能力評估基準測試Multi-IF,該基準涵蓋八種語言,包含4501個三輪對話任務,旨在更全面地評估大語言模型(LLM)在實際應用上的表現。與現有評估標準主要集中於單輪對話和單語言任務不同,Multi-IF著重考察模型在複雜多輪和多語言場景下的能力,為LLM的改進提供了更清晰的方向。
Meta 最近發布了一項全新的基準測試,名為Multi-IF,旨在評估大語言模型(LLM)在多輪對話和多語言環境下的指令遵循能力。這項基準涵蓋了八種語言,包含4501個三輪對話任務,重點探討了目前模型在複雜多輪和多語言場景中的表現。
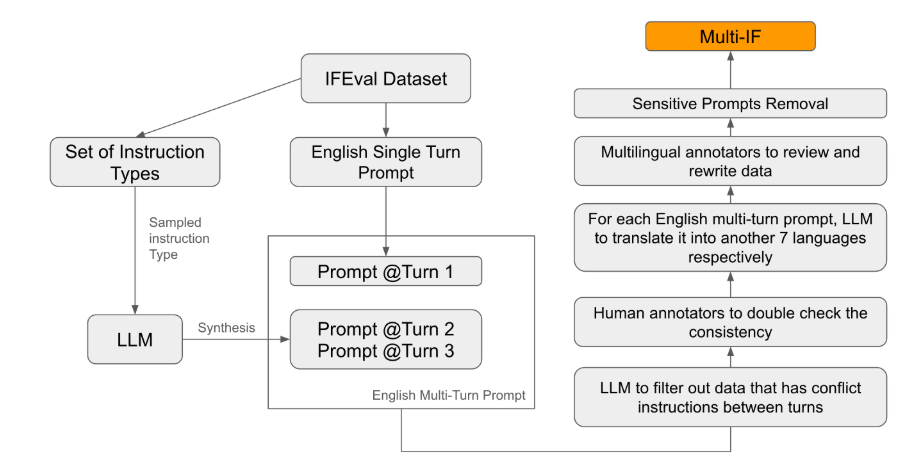
在現有的評估標準中,大多數集中在單輪對話和單語言任務,難以全面反映模型在實際應用中的表現。而Multi-IF 的推出正是為了填補這一空缺。研究團隊透過將單輪指令擴展為多輪指令,產生了複雜的對話場景,並確保每一輪指令在邏輯上連貫、遞進。此外,資料集還透過自動翻譯和手動校對等步驟實現了多語言支援。
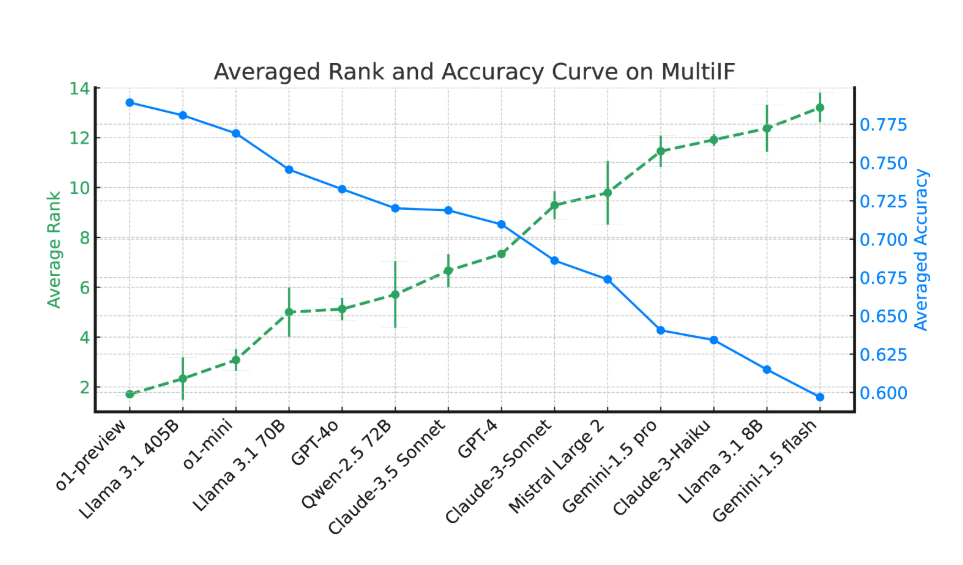
實驗結果顯示,大多數LLM 在多輪對話中的表現顯著下降。以o1-preview 模型為例,其在第一輪的平均準確率為87.7%,但到了第三輪下降至70.7%。特別是在非拉丁文字的語言中,如印地語、俄語和中文,模型的表現普遍低於英語,顯示出在多語言任務上的限制。
在14種前沿語言模型的評估中,o1-preview 和Llama3.1405B 表現最佳,三輪指令的平均準確率分別為78.9% 和78.1%。然而,在多輪對話中,所有模型的指令遵循能力普遍下降,反映出模型在複雜任務中的挑戰。研究團隊也引入了「指令遺忘率」(IFR)來量化模型在多輪對話中的指令遺忘現象,結果顯示高性能模型在這方面的表現相對較好。
Multi-IF 的發佈為研究人員提供了一個具有挑戰性的基準,推動了LLM 在全球化和多語言應用中的發展。這項基準的推出,不僅揭示了目前模型在多輪、多語言任務中的不足,也為未來改進提供了明確方向。
論文:https://arxiv.org/html/2410.15553v2
Multi-IF基準測試的發布,為大語言模型在多輪對話和多語言處理方面的研究提供了重要的參考依據,也為未來模型的改進方向指明了道路。期待未來會有更多更強大的LLM湧現,更好地應對複雜的多輪多語言任務挑戰。