GPT-4V,這款號稱「看圖說話」的神器,因其對圖形介面的理解能力不足而飽受批評。 它就像一個“螢幕瞎子”,常常點錯按鈕,令人抓狂。然而,微軟發布的OmniParser模型,有望徹底解決這個問題! OmniParser就像一個“螢幕翻譯官”,將螢幕截圖轉化為GPT-4V易於理解的結構化語言,讓GPT-4V的“眼神”變得銳利起來。 Downcodes小編將帶你深入了解這個神奇的模型,看看它如何幫助GPT-4V克服「眼盲」的缺陷,以及它背後令人驚嘆的技術。
還記得那個號稱「看圖說話」神器GPT-4V嗎?它能理解圖片內容,還能根據圖片執行任務,簡直是懶人福音!但它有個致命弱點:眼神不太好!
想像一下,你讓GPT-4V幫你點個按鈕,它卻像個「螢幕瞎子」一樣,到處亂點,是不是很抓狂?
今天就來跟大家介紹一個能讓GPT-4V眼神變好的神器- OmniParser!這是微軟發布的全新模型,旨在解決圖形使用者介面(GUI)自動互動的難題。
OmniParser是乾啥的?
簡單來說,OmniParser就是個“螢幕翻譯官”,它能把螢幕截圖解析成GPT-4V能看懂的“結構化語言”。 OmniParser結合了微調後的可互動圖示偵測模型、微調後的圖示描述模型和OCR模組的輸出。

這種組合產生了UI的結構化、類似DOM的表示,以及覆蓋了潛在可交互元素邊界框的螢幕截圖。研究人員首先使用流行網頁和圖標描述資料集創建了一個可交互圖標檢測資料集。這些資料集被用來微調專門的模型:一個用於解析螢幕上可交互區域的檢測模型和一個用於提取檢測到的元素的功能語義的描述模型。
具體來說,OmniParser會:
辨識螢幕上所有可互動的圖示和按鈕,並用框框標出來,給每個框框一個獨一無二的ID。
用文字描述每個圖示的功能,例如「設定」、「最小化」。辨識螢幕上的文字,並提取出來。
這樣一來,GPT-4V就能清楚知道螢幕上有什麼,每個東西是乾啥的,想點哪個按鈕只要告訴它ID就行了。
OmniParser有多牛?
研究人員用各種測試來考驗OmniParser,結果發現它真的能讓GPT-4V「眼神變好」!
在ScreenSpot測試中,OmniParser讓GPT-4V的準確率大幅提升,甚至超過了一些專門針對圖形介面訓練的模型。例如,在ScreenSpot 資料集上,OmniParser 的準確率提高了73%,超過了依賴底層HTML 解析的模型。值得注意的是,結合UI 元素的局部語義導致了預測準確性的顯著提升——使用OmniParser 的輸出時,GPT-4V 的圖標正確標記從70.5% 提高到93.8%。
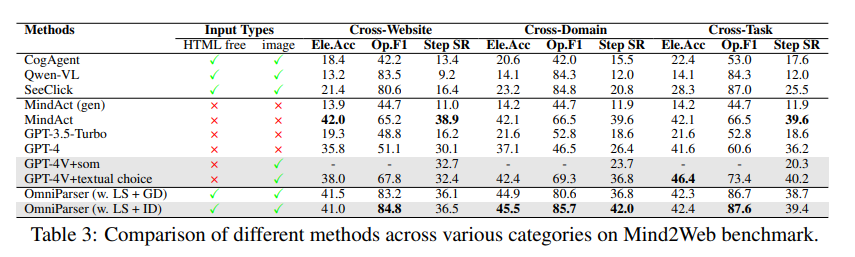
在Mind2Web測試中,OmniParser讓GPT-4V在網頁瀏覽任務中的表現更上一層樓,準確率甚至超過了使用HTML資訊輔助的GPT-4V。
在AITW測試中,OmniParser讓GPT-4V在手機導航任務中的表現也得到了顯著提升。
OmniParser還有啥不足?
雖然OmniParser很厲害,但它也有一些小毛病,例如:
面對重複的圖示或文字容易犯迷糊,需要更細緻的描述才能區分。
有時候框畫得不夠精確,導致GPT-4V點錯位置。
對圖標的理解偶爾會出錯,需要結合上下文才能更準確地描述。
不過,研究人員正在努力改進OmniParser,相信它會越來越強大,最終成為GPT-4V的最佳拍檔!
模型體驗:https://huggingface.co/microsoft/OmniParser
論文入口:https://arxiv.org/pdf/2408.00203
官方介紹:https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/
劃重點:
✨OmniParser能幫助GPT-4V更能理解螢幕內容,以便更精確地執行任務。
OmniParser在各種測試中都表現出色,證明了它的有效性。
?️OmniParser還有一些需要改進的地方,但未來可期。
總而言之,OmniParser為GPT-4V與圖形使用者介面的互動帶來了革命性的改進。雖然仍存在一些不足,但其潛力巨大,未來發展值得期待。 Downcodes小編相信,隨著科技的不斷進步,OmniParser將成為人工智慧領域的一顆閃耀的新星!