在人機互動日益頻繁的今天,流暢自然的對話體驗仍然是一個挑戰。 Downcodes小編今天要為大家介紹一款突破性技術-Kyutai實驗室研發的全雙工語音對話系統Moshi。它致力於打造更自然、更流暢的人機對話,讓人與機器的交流如同與朋友交談般輕鬆自在。 Moshi的核心創新在於其獨特的語音到語音生成方式,以及能夠同時處理多個音訊串流的先進技術,讓我們一起來深入了解Moshi的諸多亮點。
在這個數位時代,我們與機器的對話已成為日常生活的一部分。然而,這些對話往往缺乏自然度和流暢性,總是讓人感覺少了點人味兒。不過,這種情況可能即將改變。由Kyutai實驗室開發的全雙工語音對話系統Moshi,正在為我們開啟一個更自然、更流暢的人機對話新時代。
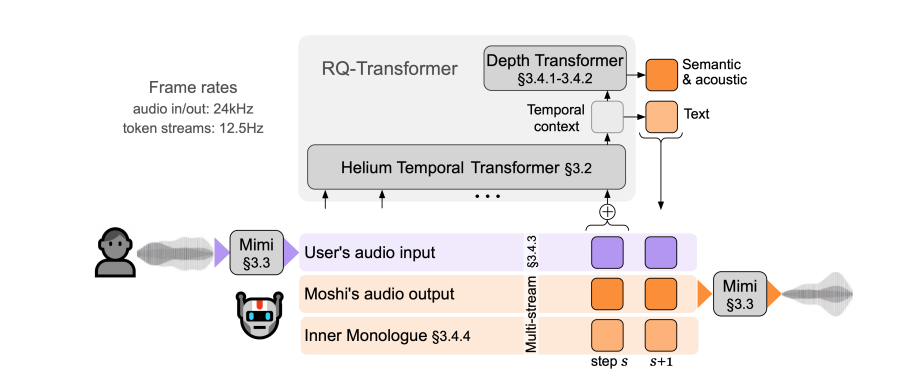
Moshi是一個基於語音和文字的對話模型,它的核心創新在於將對話視為語音到語音的生成過程。這種方法巧妙地解決了傳統語音對話系統中存在的許多問題,如延遲、資訊遺失以及輪流發言的局限性。 Moshi的獨特之處在於它能夠同時聽和說,就像我們人類一樣,能夠自如地處理對話中的重疊、打斷和插入語。
Moshi的強大功能源自於三大核心技術。首先是Helium文字語言模型,這是Moshi的大腦,擁有70億參數,透過學習大量英文數據,具備了強大的語言理解和生成能力。其次是Mimi神經音頻編解碼器,作為Moshi的嘴巴和耳朵,它能夠在語音訊號和模型可理解的離散單元之間進行轉換。最後,多流音訊語言模型是Moshi的創新之處,使其能夠同時處理多個音訊串流,實現對多個說話者聲音的同步理解。
Moshi也具備一項獨特的內在獨白功能。在產生語音之前,它會預先預測與音訊令牌同步的時間對齊文字令牌。這不僅提高了生成語音的語言質量,還能提供串流語音辨識和文字轉語音的服務,進一步增強了其對話能力。
在各項性能測試中,Moshi展現出了卓越的表現。無論是文字理解、語音可理解性、音訊品質或口語問答,Moshi都達到了現有語音-文字模型中的領先水準。這意味著,我們離真正自然流暢的人機對話又更近了一步。
然而,隨著AI技術的發展,安全性問題也日益凸顯。值得注意的是,Moshi的開發團隊在設計初就考慮到了這一點。他們採取了多項措施來確保系統的安全性,包括避免產生有害內容、保護使用者隱私和確保聲音一致性。 Moshi能夠辨識並拒絕回答不適當的問題,同時保持自身聲音的一致性,不會模仿使用者的語音,這為使用者提供了額外的安全性。
Moshi的問世不僅是技術上的突破,更預示著人機互動方式的重大革新。它為我們展示了未來對話系統的無限可能,讓我們看到了一個人與機器之間能夠進行自然、流暢、富有人情味對話的美好前景。隨著這項技術的不斷發展與完善,我們或許很快就能真正實現與機器進行無障礙、高品質的交流,讓科幻電影中的場景在現實生活中上演。
模型位址:https://huggingface.co/kyutai/moshiko-pytorch-bf16
論文網址:https://kyutai.org/Moshi.pdf
Moshi 的出現為未來人機互動指明了方向,其流暢自然的對話體驗令人期待。相信隨著科技的不斷進步,人與機器之間的交流會越來越便捷自然,最終實現真正意義上的無障礙溝通。讓我們拭目以待!