Downcodes小编报道:上海交通大学、剑桥大学和吉利汽车研究院的研究团队近日推出了名为F5-TTS的全新文本到语音(TTS)系统。该系统采用无自回归方法,结合流匹配与扩散变换器(DiT),有效简化了传统TTS模型的复杂流程,在合成质量和推理速度上均取得了显著突破。相比传统的TTS模型,F5-TTS在处理速度和鲁棒性方面表现出色,为语音合成技术带来了新的可能性。
最近,来自上海交通大学、剑桥大学和吉利汽车研究院的研究团队推出了一种全新的文本到语音(TTS)系统,名为 F5-TTS。这种系统的特别之处在于,它采用了一种无自回归的方法,结合了流匹配与扩散变换器(DiT),成功简化了传统 TTS 模型中的复杂步骤。

大家都知道,传统的 TTS 模型往往需要进行复杂的持续时间建模、音素对齐和专门的文本编码,这些都增加了合成过程的复杂性。尤其是以往的模型如 E2TTS,常常面临着收敛速度慢和文本与语音对齐不准确的问题,这让它们在现实场景中很难高效应用。而 F5-TTS 的出现,正是为了解决这些挑战。
F5-TTS 的工作原理很简单,首先将输入的文本通过 ConvNeXt 架构进行处理,使其更容易与语音进行对齐。然后,经过填充的字符序列与输入语音的噪声版本一起被输入到模型中。
该系统的训练依赖于 Diffusion Transformer(DiT),通过流匹配有效地将简单的初始分布映射到数据分布上。此外,F5-TTS 还创新性地引入了推理时的 Sway Sampling 策略,这一策略可以在推理阶段优先处理早期的流步骤,从而提高生成语音与输入文本的对齐效果。
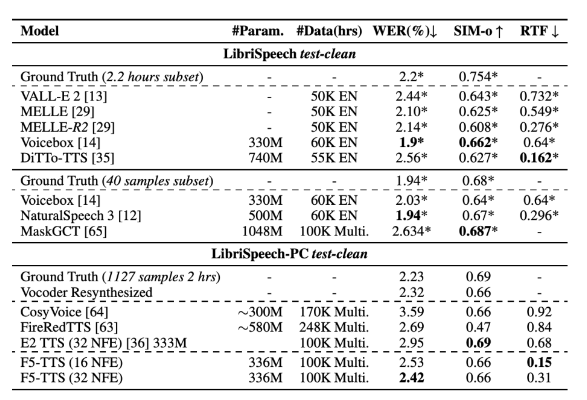
根据研究成果,F5-TTS 在合成质量和推理速度上都超越了许多当前的 TTS 系统。在 LibriSpeech-PC 数据集上,该模型的字错误率(WER)达到了2.42,并且在推理时的实时因子(RTF)为0.15,显著优于之前的扩散模型 E2TTS,后者在处理速度和鲁棒性上存在短板。
同时,Sway Sampling 策略显著提升了生成语音的自然度和可懂性,使得模型在无训练的情况下也能实现流畅且富有表现力的生成。
F5-TTS 通过简化流程,消除了对持续时间预测、音素对齐和明确文本编码的需求,提高了对齐的鲁棒性和合成质量。此外,研究人员还强调了伦理考量,提出需建立水印和检测系统,以防止该模型被滥用。
项目入口:https://github.com/SWivid/F5-TTS
划重点:
F5-TTS 是一种新型无自回归文本到语音系统,简化了传统 TTS 模型的复杂性。
该系统利用 ConvNeXt 和 DiT 架构,提高了文本与语音的对齐效果,显著提升了合成质量。
? 研究人员强调需关注伦理问题,建议引入水印和检测机制,防止潜在的滥用。
F5-TTS系统的出现,为文本到语音技术带来了新的突破,其高效的性能和简化的流程有望在诸多领域得到广泛应用。然而,伦理问题也需要引起重视,后续的研究应致力于建立完善的监管机制,确保技术的负责任发展。