Downcodes小編帶你了解AI領域一個令人不安的現象-模型崩潰。想像一下,一個AI模型像個吃播博主,開始吃自己做的菜,而且越吃越上癮,菜也越來越難吃,最終“吃壞肚子”,這就是模型崩潰。它發生在AI模型過度依賴自身產生的資料時,導致模型品質下降,甚至完全失效。這篇文章將深入探討模型崩潰的成因、影響以及如何避免它。
最近AI圈發生了一件怪事,就像吃播部落客突然開始吃自己做的菜,而且越吃越上癮,菜也越來越難吃。這事兒說起來還蠻嚇人,專業的術語叫做模型崩潰(model collapse)。
模型崩潰是啥?簡單來說,就是AI模型在訓練過程中,如果大量使用自己產生的數據,就會陷入一個惡性循環,導致模型生成的質量越來越差,最終完犢子。
這就像一個封閉的生態系統,AI模型就是這個系統裡的唯一生物,它所生產的食物就是數據。一開始,它還能找到一些天然的食材(真實數據),但隨著時間的推移,它開始越來越依賴自己生產的「人造」食材(合成數據)。問題是,這些「人造」食材營養不良,而且還帶有模型本身的一些缺陷。吃太多了,AI模型的「身體」就垮了,生成的東西也越來越離譜。
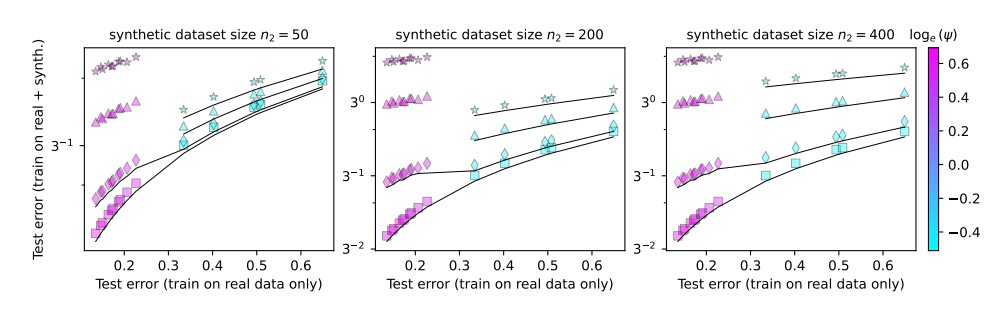
這篇論文就研究了模型崩潰現象,並試圖回答兩個關鍵問題:
模型崩潰是不可避免的嗎?能不能透過混合真實數據和合成數據來解決問題?
模型越大,是不是越容易崩潰?
為了研究這些問題,論文作者設計了一系列實驗,並用隨機投影模型來模擬神經網路的訓練過程。他們發現,就算只使用一小部分合成資料(例如1%),也可能導致模型崩潰。更糟的是,隨著模型規模的增加,模型崩潰的現象會更加嚴重。
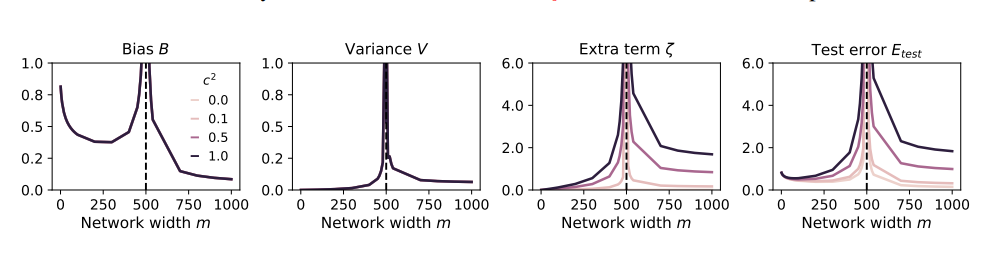
這就好比吃播部落客為了吸引眼球,開始嘗試各種奇葩食材,結果吃壞了肚子。為了挽回損失,他只能加大食量,吃更多更奇葩的東西,結果肚子越來越糟糕,最後只能退出吃播界。
那麼,我們該如何避免模型崩潰呢?
論文作者們提出了一些建議:
優先使用真實數據:真實數據就像天然食材,營養豐富,是AI模型健康成長的關鍵。
謹慎使用合成數據:合成數據就像人造食材,雖然可以補充一些營養,但不能過度依賴,否則會適得其反。
控制模型規模:模型越大,胃口越大,越容易吃壞肚子。使用合成資料時,要控制模型的規模,避免過度餵食。
模型崩潰是AI發展過程中遇到的新挑戰,它提醒我們,在追求模型規模和效率的同時,也要關注數據的品質和模型的健康。這樣,才能讓AI模型持續健康發展,為人類社會創造更大的價值。
論文:https://arxiv.org/pdf/2410.04840
總而言之,模型崩潰是AI發展中一個值得關注的問題,我們需要謹慎對待合成數據,重視真實數據的質量,並控制模型規模,才能避免「AI吃壞肚子」的現象發生。希望這篇分析能幫助大家更理解模型崩潰,並為AI的健康發展做出貢獻。