Downcodes小編為您帶來重磅消息!人工智慧領域再添新成員-Zyphra公司正式發布了其小型語言模型Zamba2-7B!這款70億參數的模型,在性能上實現了突破,尤其是在效率和適應性方面,展現出令人矚目的優勢。它不僅適用於高效能運算環境,更重要的是,Zamba2-7B 也能運作在消費級GPU上,讓更多用戶能夠輕鬆體驗先進AI技術的魅力。本文將深入探討Zamba2-7B的創新之處,以及它對自然語言處理領域的影響。
最近,Zyphra 正式推出了Zamba2-7B,這是一款具有前所未有性能的小型語言模型,參數數量達到7B。
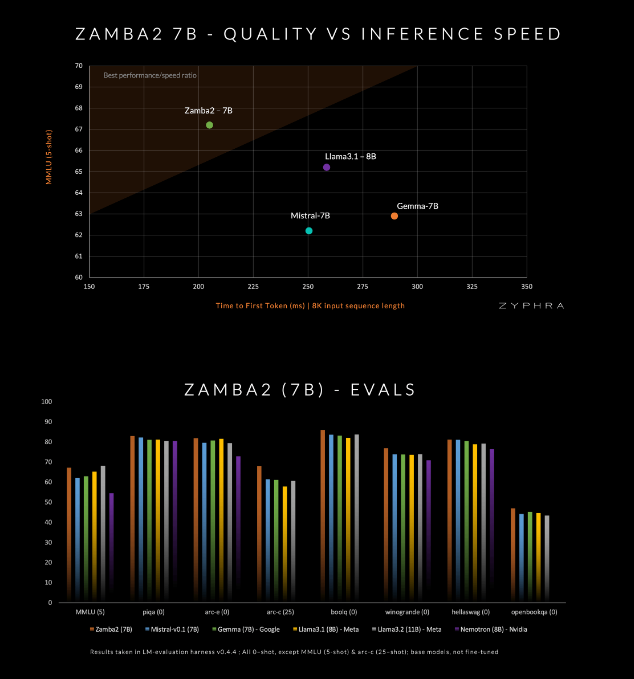
這款模型號稱在品質和速度上超越了目前的競爭對手,包括Mistral-7B、Google的Gemma-7B 以及Meta 的Llama3-8B。
Zamba2-7B 的設計目標是滿足那些需要強大語言處理能力但又受限於硬體條件的環境,例如在裝置上處理或使用消費級GPU。透過提高效率而不犧牲質量,Zyphra 希望能讓更廣泛的用戶,無論是企業還是個人開發者,都能享受先進AI 的便利。
Zamba2-7B 在架構上做了很多創新,提升了模型的效率和表達能力。與前一代模型Zamba1不同,Zamba2-7B 採用了兩個共享注意力塊,這種設計能更好地處理資訊流和序列之間的依賴關係。
Mamba2區塊構成了整個架構的核心,這使得模型的參數利用率相比傳統的變換器模型更高。此外,Zyphra 還在共享的MLP 區塊上使用了低秩適應(LoRA)投影,這進一步提高了每一層的適應性,同時保持了模型的緊湊性。由於這些創新, Zamba2-7B 的首次回應時間減少了25%,每秒處理的token 數量提升了20%。
Zamba2-7B 的高效率和適應性得到了嚴格測試的驗證。該模型在一個包含三萬億token 的海量資料集上進行預訓練,這些資料集都是高品質和經過嚴格篩選的開放資料。
此外,Zyphra 還引入了一種「退火」 預訓練階段,快速降低學習率,以便更有效地處理高品質token。這種策略讓Zamba2-7B 在基準測試中表現出色,在推理速度和品質上都超越了競爭對手,適合處理自然語言理解和生成等任務,而不需要傳統高品質模型所需的巨量計算資源。
amba2-7B 代表了小型語言模型的一個重大進步,它在保持高品質和高效能的同時,也特別注重了可訪問性。 Zyphra 透過創新的架構設計和高效的訓練技術,成功打造出不僅方便使用,同時又能滿足各種自然語言處理需求的模型。 Zamba2-7B 的開源發布,邀請研究人員、開發者和企業探索其潛力,並有望在更廣泛的社區中推進高級自然語言處理的發展。
專案入口:https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
Zamba2-7B的開源發布,為自然語言處理領域帶來了新的活力,也為開發者提供了更多可能性。期待Zamba2-7B未來能有更廣泛的應用,推動人工智慧技術持續進步!