Downcodes小編報:一個名為Meissonic的開源AI影像生成模型橫空出世,它只使用十億個參數,就能產生高品質影像,堪稱AI影像生成領域的輕量級巨頭!這得歸功於研發團隊(阿里巴巴、Skywork AI及多所大學的研究者)所採用的獨特變換器架構和新穎的訓練方法。 Meissonic不僅能在普通遊戲PC上運行,未來更有望在手機上實現在地化文字轉影像應用,這將大大降低AI影像產生的准入門檻。
最近,科學研究團隊共同推出了一款名為Meissonic 的開源AI 影像生成模型。驚喜的是,這款模型只使用了十億個參數,卻能產生高品質的影像。這種緊湊的設計讓Meissonic 有潛力在行動裝置上實現在地化的文字轉圖像應用。

這項技術的背後,研發團隊包括阿里巴巴、Skywork AI 以及多所大學的研究者。他們採用了一種獨特的變換器架構和新穎的訓練方法,使得Meissonic 能夠在普通遊戲PC 上運行,甚至未來可能在手機上使用。
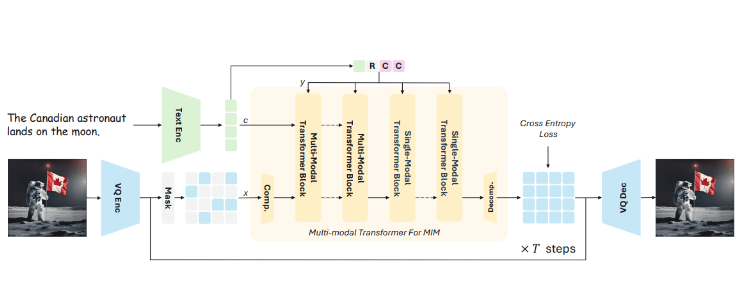
Meissonic 的訓練方法採用了一種被稱為「遮蔽影像建模」 的技術,簡單來說,就是在訓練過程中會隱藏影像的一部分。模型學習如何根據可見的區域和文字描述來重建缺少的部分。這種方式幫助模型理解圖像元素和文字之間的關係。
Meissonic 的架構讓它能夠產生1024x1024像素的高解析度影像,無論是逼真的場景還是風格化的文字、表情包,甚至是卡通貼紙,都能輕鬆應付。
與傳統的自回歸模型逐步生成影像不同,Meissonic 則是透過並行的迭代優化來同時預測所有的影像訊息,這項創新顯著減少了解碼的步驟,大約減少了99% 的時間,大幅提升了影像生成的速度。
在模型的建構過程中,研究者們經歷了四個步驟:
首先,他們用2億張256x256像素的圖像教授模型基本概念;接著,用1000萬對經過嚴格篩選的圖像- 文本對提升其文本理解能力;然後,通過增加特殊的壓縮層,使得模型能夠輸出1024x1024像素的圖像;最後,他們進行了微調,結合人類偏好的數據來提升模型的性能。

有趣的是,儘管Meissonic 的參數量較小,但在多項基準測試中表現優於一些更大的模型,例如SDXL 和DeepFloyd-XL,其在「人類偏好分數」 上獲得了28.83的高分。此外,Meissonic 還能夠在不額外訓練的情況下進行影像的修補和擴展,讓使用者可以輕鬆添加缺少的影像部分或創造性地增強現有的影像。
研究團隊認為,這種方法可能會促進客製化AI 影像生成器的快速、低成本開發,也有望推動行動裝置上文字轉影像應用的發展。有興趣的朋友可以在Hugging Face 上找到演示版本,並在GitHub 上查看模型的程式碼,使用普通8GB 顯存的消費者GPU 便可輕鬆運行。
demo:https://huggingface.co/spaces/MeissonFlow/meissonic
項目:https://github.com/viiika/Meissonic
劃重點:
Meissonic 是一款僅用十億個參數就能產生高品質影像的開源AI 模型,適合一般遊戲PC 和未來的行動裝置使用。
採用平行迭代優化的訓練方法,Meissonic 在影像生成速度上比傳統模型快99%。
? 儘管參數量小,Meissonic 在多項測試中表現超越更大模型,且能實現無訓練的影像修補和擴展功能。
總而言之,Meissonic 的出現為AI影像生成領域帶來了新的可能性,其輕量級設計和高效的性能值得期待! Downcodes小編建議大家前往Hugging Face和GitHub體驗和探索這款強大的AI模型。