Downcodes小編帶你了解瑞士洛桑聯邦理工學院(EPFL)最新研究成果!該研究深入比較了兩種主流大型語言模型(LLM) 的適應性訓練方法:上下文學習(ICL) 和指令微調(IFT),並使用MT-Bench 基準測試對模型遵循指令的能力進行了評估。研究結果顯示,兩種方法在不同場景下各有千秋,為LLM 的訓練方法選擇提供了寶貴的參考。
瑞士洛桑聯邦理工學院(EPFL) 的一項最新研究比較了兩種主流的大型語言模型(LLM) 適應性訓練方法:上下文學習(ICL) 和指令微調(IFT)。研究人員使用MT-Bench 基準測試來評估模型遵循指令的能力,發現在特定情況下,兩種方法的表現各有優劣。
研究發現,當可用的訓練樣本數量較少時(例如不超過50個),ICL 和IFT 的效果非常接近。這顯示在數據有限的情況下,ICL 或許可以作為IFT 的替代方案。
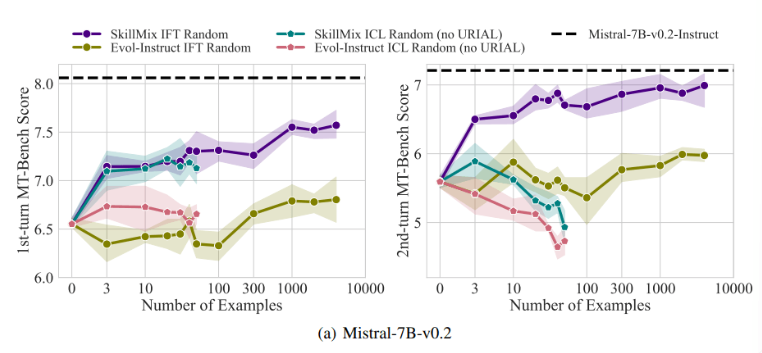
然而,隨著任務複雜度的增加,例如在多輪對話場景中,IFT 的優勢變得明顯。研究人員認為,ICL 模型容易過度擬合到單一樣本的風格,導致在處理複雜對話時表現不佳,甚至不如基礎模型。
研究也檢視了URIAL 方法,這種方法只使用三個樣本和指令遵循規則來訓練基礎語言模型。雖然URIAL 取得了一定的效果,但與經過IFT 訓練的模型相比仍有差距。 EPFL 的研究人員透過改進樣本選擇策略,提升了URIAL 的效能,使其接近微調模型。這凸顯了高品質訓練資料對ICL、IFT 以及基礎模型訓練的重要性。
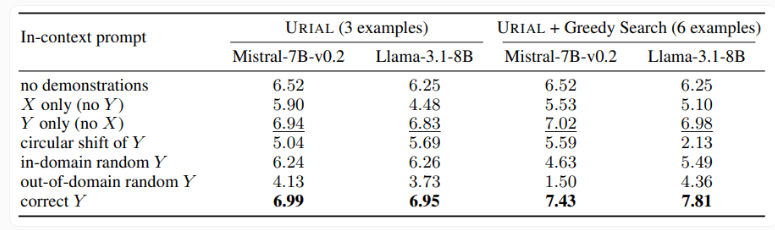
此外,研究也發現解碼參數對模型效能有顯著影響。這些參數決定了模型如何產生文本,對基礎LLM 和使用URIAL 訓練的模型都至關重要。
研究人員指出,即使是基礎模型,在適當的解碼參數下也能在一定程度上遵循指示。
這項研究的意義在於,它揭示了情境學習可以快速有效地調整語言模型,尤其是在訓練樣本有限的情況下。但對於多輪對話等複雜任務,指令微調仍是更優的選擇。
隨著資料集規模的擴大,IFT 的效能會持續提升,而ICL 的效能在達到一定樣本數後會趨於穩定。研究人員強調,選擇ICL 還是IFT 取決於多種因素,例如可用資源、資料量和特定應用需求。無論選擇哪種方法,高品質的訓練資料至關重要。
總而言之,EPFL 的研究為大型語言模型的訓練方法選擇提供了新的見解,也為未來的研究方向指明了道路。選擇ICL 或IFT 需要根據具體情況權衡利弊,高品質的數據始終是關鍵。希望這項研究能幫助大家更理解和應用大型語言模式。