Downcodes小編帶你了解智源研究院最新發表的多模態世界模型Emu3! Emu3憑藉其獨特的「下一個token預測」能力,在文字、圖像和影片三種模態上實現了突破性的理解和生成能力。它不僅能產生高品質影像和流暢自然的視頻,還能進行精準的影像理解和影片預測,其性能更超越了許多知名開源模型。 Emu3的開源特性也為多模態AI的發展注入了新的活力,讓我們一起探索背後的技術創新和未來潛力。
智源研究院正式發布了他們的新一代多模態世界模型Emu3,該模型的最大亮點在於,它僅依靠下一個token 的預測能力,就能在文本、圖像和視頻這三種不同模態中進行理解和生成。

在影像生成方面,Emu3能夠根據視覺token 預測生成高品質的影像。這意味著用戶可以期待靈活的解析度和多樣的風格。

而在視頻生成方面,Emu3則以一種全新的方式工作,不同於其他模型通過噪聲生成視頻,Emu3通過順序預測直接生成視頻。這種技術的進步使得視訊生成變得更加流暢自然。

在影像生成、視訊生成和視覺語言理解等任務上,Emu3的表現都超過了許多知名的開源模型,如SDXL、LLaVA 和OpenSora。背後是一個強大的視覺tokenizer,能夠將視訊和圖像轉換為離散的token,這樣的設計為統一處理文字、圖像和視訊提供了新的想法。
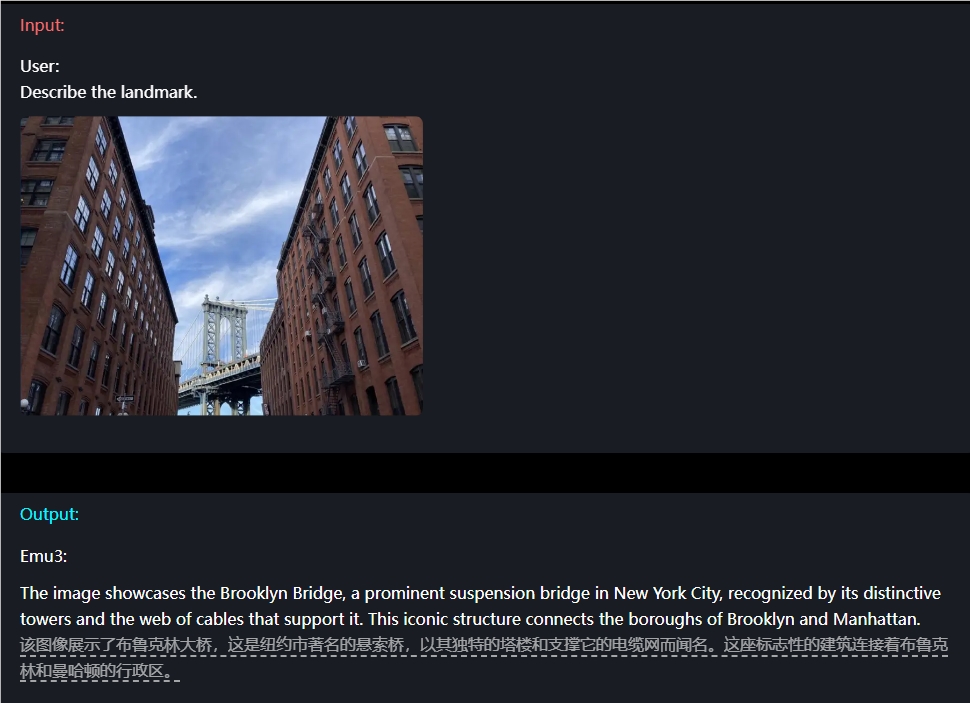
比方說,在影像理解方面,使用者只需簡單輸入一個問題,Emu3就能精準描述出影像內容。
Emu3也具備視訊預測能力。當給定一個影片時,Emu3可以基於現有的內容,預測接下來會發生什麼。這使得它在模擬環境、人類和動物行為方面顯示出了強大的能力,能夠讓使用者感受到更真實的互動體驗。

此外,Emu3的設計彈性也讓人耳目一新。它可以直接與人類的偏好進行最佳化,這樣產生的內容更符合使用者的期待。而且,Emu3作為一個開源模型,吸引了技術社群的熱議,許多人認為這項成果將徹底改變多模態AI 的發展格局。
專案網址:https://emu.baai.ac.cn/about
論文:https://arxiv.org/pdf/2409.18869
劃重點:
Emu3透過下一個token 的預測,實現了文字、圖像和影片的多模態理解與生成。
在多個任務上,Emu3的效能超越了多款知名開源模型,展現出強大的能力。
Emu3的靈活設計與開源特性,為開發者提供了新的機會,有望推動多模態AI 的創新與發展。
Emu3的出現,標誌著多模態AI領域邁向了一個新的里程碑。其強大的性能、靈活的設計以及開源的特性,無疑將對未來的AI發展產生深遠的影響。期待Emu3能在更多領域得到應用,為人類帶來更多便利與驚喜!