Downcodes小編獲悉,北京智源人工智慧研究院聯合多所大學推出了名為Video-XL的超長影片理解大模型。該模型在處理超過十分鐘的長影片方面表現出色,在多個基準評測中取得領先地位,展現了強大的泛化能力和處理效率。 Video-XL利用語言模型對長視覺序列進行壓縮,並在「海中撈針」等任務中達到近95%的準確率,僅需80G顯存的顯示卡即可處理2048幀輸入。此模型的開源,將促進全球多模態視訊理解研究社群的合作與發展。
北京智源人工智慧研究院聯合上海交通大學、中國人民大學、北京大學和北京郵電大學等大學推出了名為Video-XL的超長視訊理解大模型。這款模型是多模態大模型核心能力的重要展現,也是邁向通用人工智慧(AGI)的關鍵步驟。與現有多模態大模型相比,Video-XL在處理超過10分鐘的長影片時,展現了更優的效能和效率。

Video-XL利用語言模型(LLM)的原生能力,對長視覺序列進行壓縮,保留了短視頻理解的能力,並在長視頻理解上顯示出了卓越的泛化能力。該模型在多個主流長影片理解基準評測的多項任務中均排名第一。 Video-XL在效率與性能之間實現了良好平衡,僅需一塊80G顯存的顯示卡即可處理2048幀輸入,對小時長度視頻進行採樣,並在視頻“海中撈針”任務中取得了接近95 %的準確率。
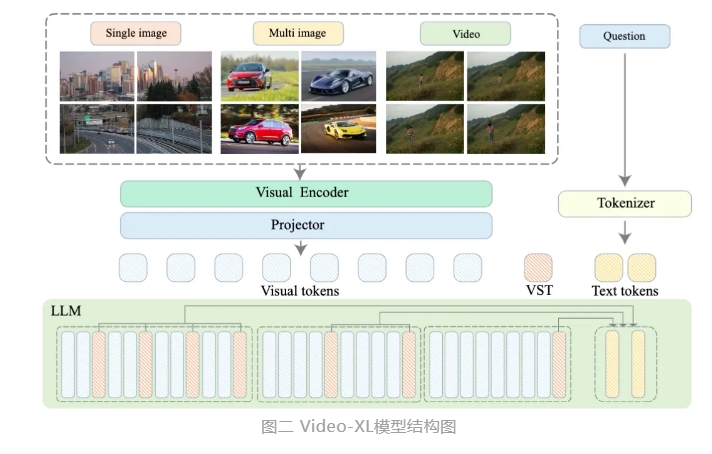
Video-XL預計在電影摘要、視訊異常檢測、廣告植入檢測等應用場景中展現廣泛的應用價值,成為長視訊理解的得力助手。該模型的推出,標誌著長視訊理解技術在效率和準確性上邁出了重要一步,為未來長視訊內容的自動化處理和分析提供了強有力的技術支援。
目前,Video-XL的模型程式碼已經開源,以促進全球多模態視訊理解研究社群的合作和技術共享。
論文標題:Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
論文連結:https://arxiv.org/abs/2409.14485
模型連結:https://huggingface.co/sy1998/Video_XL
專案連結:https://github.com/VectorSpaceLab/Video-XL
Video-XL的開源,為長視訊理解領域的研究和應用帶來了新的可能性,其高效性和準確性將推動相關技術的進一步發展,並為未來更多應用場景提供技術支援。期待未來能看到更多基於Video-XL的創新應用。