Downcodes小編帶您了解德國達姆施塔特工業大學的一項最新研究。該研究以Bongard問題為測試工具,評估了目前最先進AI影像模型在簡單視覺推理任務中的表現。研究結果令人意外,即使是像GPT-4o這樣的頂尖多模態模型,其準確率也遠低於預期,這引發了對現有AI視覺能力評估標準的深刻反思。
來自德國達姆施塔特工業大學的最新研究揭示了一個令人深思的現象:即便是當前最先進的AI圖像模型,在面對簡單的視覺推理任務時也會出現明顯失誤。這項研究結果對AI視覺能力的評估標準提出了新的思考。
研究團隊採用了由俄國科學家Michail Bongard設計的Bongard問題作為測試工具。這類視覺謎題由12張簡單影像組成,分成兩組,要求辨識出區分這兩組的規則。對大多數人來說,這種抽象推理任務並不困難,但AI模型的表現卻令人意外。
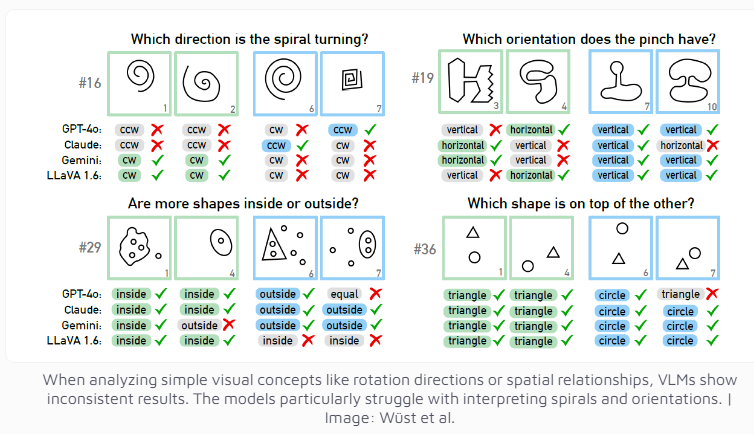
即便是目前被認為最先進的多模態模型GPT-4o,在100個視覺謎題中也僅成功解決了21個。其他知名AI模式如Claude、Gemini和LLaVA的表現則較不盡人意。這些模型在辨識垂直和水平線條,或判斷螺旋方向等基礎視覺概念時都表現出明顯的困難。
研究人員發現,即使在提供多項選擇的情況下,AI模型的表現也僅有輕微提升。只有在嚴格限制可能答案數量的條件下,GPT-4和Claude的成功率才分別提升至68個和69個謎題。透過深入分析四個特定案例,研究團隊發現AI系統有時在達到思考和推理階段之前,就已經在基礎視覺感知層面出現了問題,但具體原因仍難以確定。
這項研究也引發了對AI系統評估標準的反思。研究團隊指出:為什麼視覺語言模型在已建立的基準測試中表現出色,卻在看似簡單的Bongard問題上遇到困難?這些基準測試在評估真實推理能力方面的意義究竟有多大?這些問題的提出,暗示了當前AI評估體係可能需要重新設計,以更準確地衡量AI的視覺推理能力。
這項研究不僅展示了目前AI技術的局限性,也為未來AI視覺能力的發展指明了方向。它提醒我們,在為AI的快速進步歡呼之際,也要清醒地認識到AI在基礎認知能力方面仍有待提升的空間。
這項研究清楚地表明,AI模型在視覺推理方面仍有很大的進步空間,未來需要更有效的評估方法和技術突破來提升AI的認知能力。 Downcodes小編將持續關注AI領域的前沿進展,為您帶來更多精彩報導。