Downcodes小编获悉,阿里云重磅推出全新的大规模音频语言模型Qwen2-Audio,该模型在语音交互领域取得了显著突破。它能够接受多种音频信号输入,并进行音频分析或直接回答语音指令,极大地提升了用户体验。相比于之前的Qwen-Audio模型,Qwen2-Audio在指令跟踪方面展现出更强大的性能,在多个基准测试中取得了领先地位。这标志着阿里云在人工智能领域又迈出了坚实的一步,为用户带来了更先进、更便捷的语音交互技术。
阿里云最新发布了一名为 Qwen-Audio 的大规模音频语言型,该模型可接受多种音频信号输入,够进行音频分析或直接回答语音指令极大地提升了语音交互体验。
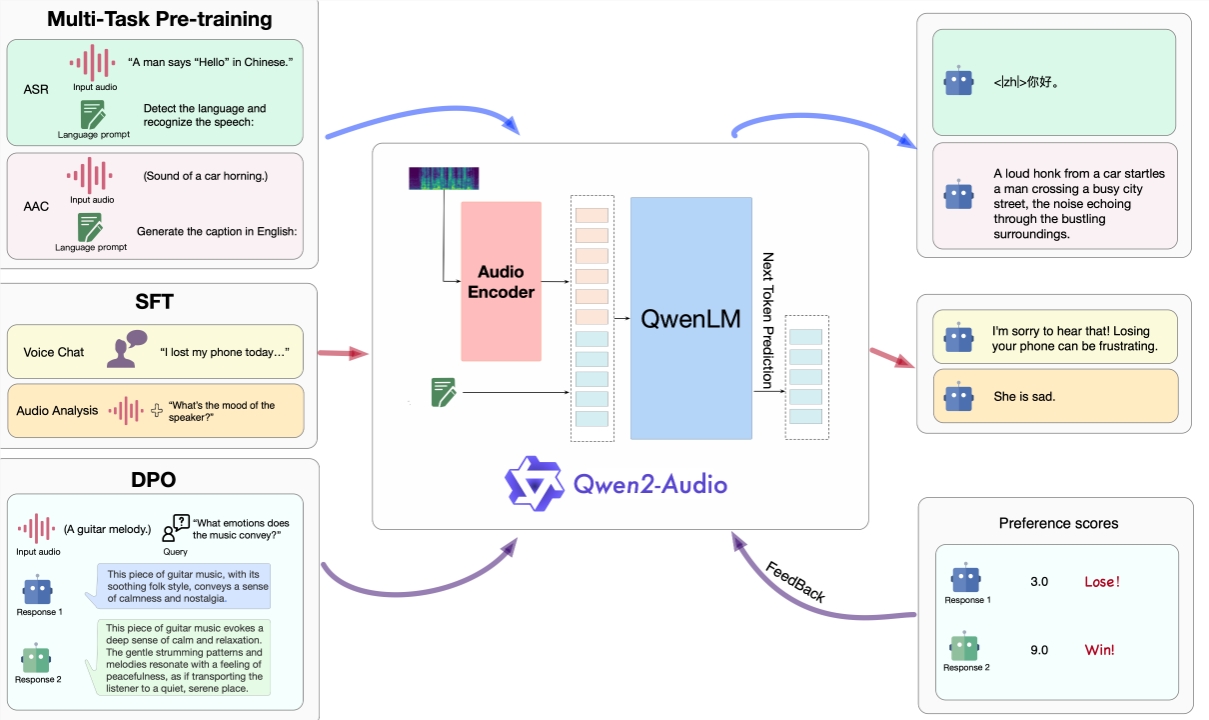
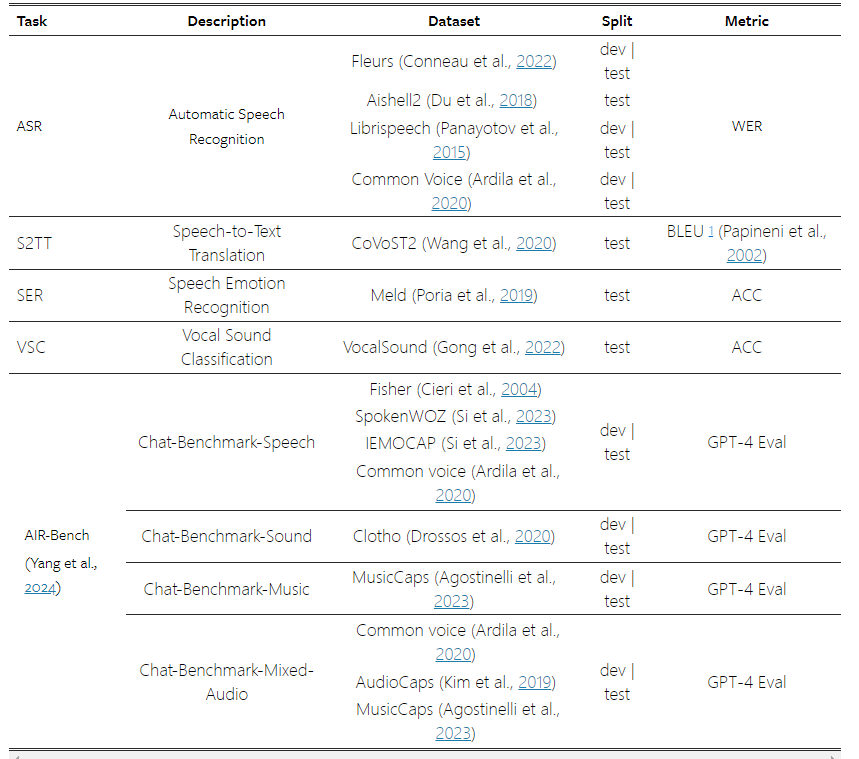
Qwen2-Audio的聊天能力方面,研究人员在AIR-Bench的聊天基准上测量了其性能(Yang et al.,2024),Qwen2-Audio 展示了跨语音、声音音乐和混合音频子集的最先进的 (SOTA) 指令跟踪功能。与 Qwen-Audio 相比,它显示出实质性的改进,并且显着优于其他 LALM。
划重点:
阿里云发布 Qwen2-Audio,一款革新性的大规模频语言模型,提升了语音交互体验;
Qwen2-Audio 可接受多种音频信号输入进行音频分析或直接回答语音指令,大地拓展了语音交互功能;
通过三段训练过程,Qwen2-Audio 的模型结构训练方法和性能表现得到了全面展示为用户带来更加优质的音频交互体验。
总而言之,Qwen2-Audio的出现为语音交互技术带来了新的可能性,其强大的性能和多功能性使其在未来应用中拥有广阔前景。Downcodes小编将持续关注阿里云在人工智能领域的最新进展,为读者带来更多精彩报道。