Downcodes小編帶你揭露視覺語言模型(VLMs)的真相!你以為VLMs能像人類一樣「看懂」影像?事實並非如此簡單。本文將深入探討VLMs在圖像理解方面的局限性,並透過一系列實驗結果,展現它們與人類視覺能力的巨大差距。準備好顛覆你對VLMs的認知了嗎?
視覺語言模型(VLMs)大家應該都聽過,這些AI界的小能手不僅能讀懂文字,還能「看」懂圖片。但事實並非如此,今天,我們來扒一扒它們的“底褲”,看看它們是否真的像我們人類一樣能“看”懂圖像。
首先,得給大家科普一下,VLMs是啥玩意兒。簡單來說,它們就是一些大型的語言模型,例如GPT-4o和Gemini-1.5Pro,它們在圖像和文字處理上表現得風生水起,甚至在許多視覺理解測試上都拿到了高分。但別被這些高分唬住,我們今天要去看看它們是不是真的那麼牛。
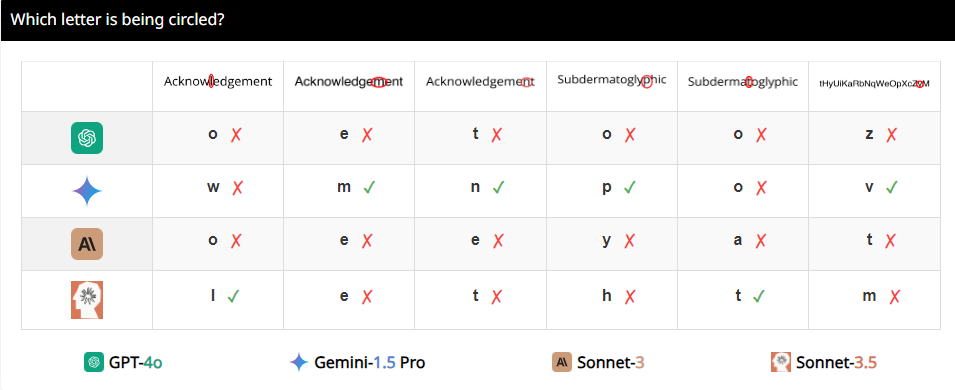
研究人員設計了一套叫做BlindTest的測試,裡面有7個任務,對人類來說簡直簡單到不行。例如,判斷兩個圓是否重疊,兩條線是否相交,或是數數奧運標誌裡有幾個圓圈。這些任務聽起來是不是覺得幼兒園小朋友都能輕鬆搞定?但告訴你,這些VLMs的表現可沒那麼神。
結果讓人大跌眼鏡,這些所謂的先進模型在BlindTest上的平均準確率只有56.20%,最好的Sonnet-3.5也就73.77%的準確率。這就好比一個號稱能考清華北大的學霸,結果連小學數學題都做不對。

為啥會這樣呢?研究人員分析,可能是因為VLMs在處理影像時,就像是個近視眼,看不清楚細節。它們雖然能大致看出影像的整體趨勢,但一旦涉及到精確的空間訊息,例如兩個圖形是否相交,或者重疊,它們就懵了。
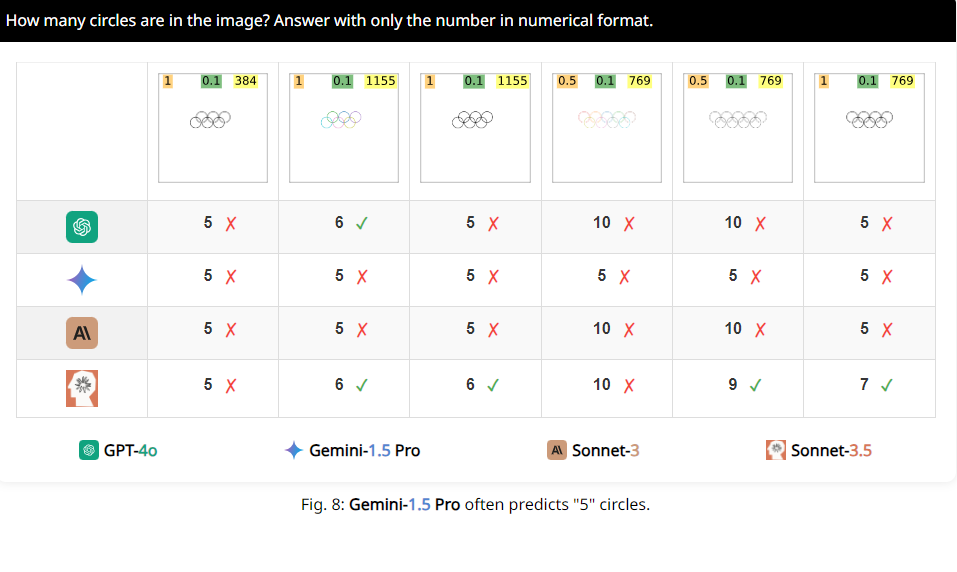
舉個例子,研究人員請VLMs判斷兩個圓是否重疊,結果發現,即使兩個圓大得跟西瓜似的,這些模型還是不能100%準確地回答出來。還有,當讓它們數數奧運標誌裡的圓圈數,它們的表現也是一言難盡。
更有意思的是,研究人員也發現,這些VLMs在數數時,似乎對數字5有一種特別的偏好。例如,當奧運標誌裡的圓圈數超過5個時,它們就傾向於回答“5”,這可能是因為奧運標誌裡有5個圓圈,它們對這個數字特別熟悉。
好了,說了這麼多,小伙伴們是不是對這些看似高大上的VLMs有了新的認識?其實,它們在視覺理解上還有很多局限,遠沒有達到我們人類的水平。所以,下次再聽到有人說AI能完全取代人類,你就可以呵呵一笑了。
論文網址:https://arxiv.org/pdf/2407.06581
專案頁:https://vlmsareblind.github.io/
總而言之,儘管VLMs在影像辨識領域取得了顯著進展,但在精確空間推理方面的能力仍有較大不足。這項研究提醒我們,AI技術的評估不能只依賴高分成績,更需要深入了解其局限性,避免盲目樂觀。期待未來VLMs能夠在視覺理解上取得突破性進展!