Downcodes小編帶你了解Google DeepMind一項突破性研究:百萬專家混合模型(Mixture of Experts,MoE)。這項研究在Transformer架構上取得了革命性進展,其核心在於一種參數高效的專家檢索機制,利用乘積密鑰技術平衡計算成本與參數數量,從而在保持效率的同時大幅提升模型潛力。這項研究不僅探索了極端MoE設置,更首次證明了學習索引結構可以有效地路由到超過百萬個專家,為AI領域帶來新的可能性。
Google DeepMind提出的百萬專家Mixture模型,一個在Transformer架構上邁出了革命性步伐的研究。
想像一下,一個能夠從一百萬個微型專家中進行稀疏檢索的模型,這聽起來是不是有點像科幻小說裡的情節?但這正是DeepMind的最新研究成果。這項研究的核心是一種參數高效的專家檢索機制,它利用乘積密鑰技術,將計算成本與參數計數分離,從而在保持計算效率的同時,釋放了Transformer架構的更大潛力。
這項工作的亮點在於,它不僅探索了極端MoE設置,還首次證明了學習索引結構可以有效地路由到超過一百萬個專家。這就好比在茫茫人海中,迅速找到那幾個能夠解決問題的專家,而且這一切還都是在計算成本可控的前提下完成的。
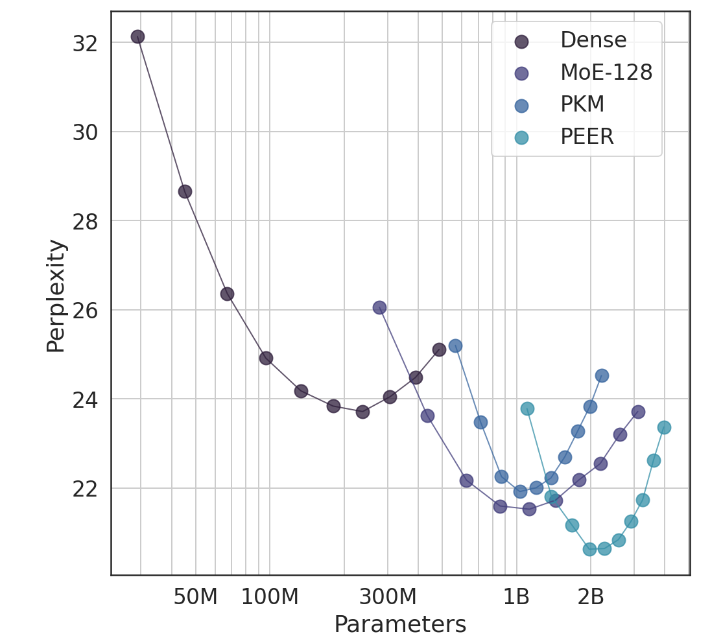
在實驗中,PEER架構展現了卓越的運算效能,與密集的FFW、粗粒度MoE和產品金鑰記憶體(PKM)層相比,其效率更高。這不僅是理論上的勝利,更是在實際應用上的巨大飛躍。透過實證結果,我們可以看到PEER在語言建模任務中的優越表現,它不僅困惑度更低,而且在消融實驗中,透過調整專家數量和活躍專家的數量,PEER模型的表現得到了顯著提升。
這項研究的作者,Xu He(Owen),是Google DeepMind的研究科學家,他的這次單槍匹馬的探索,無疑為AI領域帶來了新的啟示。正如他所展示的,透過個人化和智慧化的方法,我們能夠顯著提升轉換率,留住用戶,這在AIGC領域尤其重要。
論文網址:https://arxiv.org/abs/2407.04153
總而言之,Google DeepMind的百萬專家混合模型研究為大型語言模型的建構提供了新的思路,其高效的專家檢索機制和優異的實驗結果都預示著未來AI模型發展的巨大潛力。 Downcodes小編期待更多類似的突破性研究成果出現!