近年来,大型语言模型(LLM)的革新层出不穷,不断挑战着现有架构的极限。Downcodes小编获悉,斯坦福、UCSD、UC伯克利和Meta的研究人员联合提出了一种名为TTT(Test-Time-Training layers)的全新架构,它以其突破性的设计,有望彻底改变我们对语言模型的认知和应用方式。TTT架构通过巧妙地结合RNN和Transformer的优势,在保证线性复杂度的同时,显著提升了模型的表达能力,尤其在处理长文本时表现出色,为长视频建模等领域带来了新的可能性。
在AI的世界里,变革总是在不经意间到来。就在最近,一个名为TTT的全新架构横空出世,它由斯坦福、UCSD、UC伯克利和Meta的研究人员共同提出,一夜间颠覆了Transformer和Mamba,为语言模型带来了革命性的改变。
TTT,全称Test-Time-Training layers,是一种全新的架构,它通过梯度下降压缩上下文,直接替代了传统的注意力机制。这一方法不仅提高了效率,更解锁了具有表现力记忆的线性复杂度架构,让我们能够在上下文中训练包含数百万甚至数十亿个token的LLM。

TTT层的提出,是基于对现有RNN和Transformer架构的深刻洞察。RNN虽然效率高,但受限于其表达能力;而Transformer虽然表达能力强,但计算成本随上下文长度线性增长。TTT层则巧妙地结合了两者的优点,既保持了线性复杂度,又增强了表达能力。
在实验中,TTT-Linear和TTT-MLP两种变体均展现出了卓越的性能,它们在短上下文和长上下文中均超越了Transformer和Mamba。特别是在长上下文的场景下,TTT层的优势更加明显,这为长视频建模等应用场景提供了巨大的潜力。
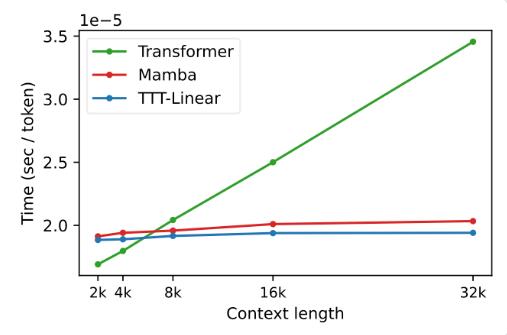
TTT层的提出,不仅在理论上具有创新性,更在实际应用中展现出了巨大的潜力。未来,TTT层有望应用于长视频建模,通过密集采样帧来提供更丰富的信息,这对于Transformer来说是一种负担,但对于TTT层来说却是一种福音。
这项研究是团队五年磨一剑的成果,从Yu Sun博士的博士后时期就开始酝酿。他们坚持探索,不断尝试,最终实现了这一突破性的成果。TTT层的成功,是团队不懈努力和创新精神的结晶。
TTT层的问世,为AI领域带来了新的活力和可能性。它不仅改变了我们对语言模型的认识,更为未来的AI应用开辟了新的道路。让我们一起期待TTT层在未来的应用和发展,见证AI技术的进步和突破。
论文地址:https://arxiv.org/abs/2407.04620
TTT架构的出现,无疑为AI领域注入了一针强心剂,其在长文本处理方面的突破性进展,预示着未来AI应用将拥有更强大的处理能力和更广阔的应用前景。让我们拭目以待,看看TTT架构将如何进一步改变我们的世界。