Downcodes小編為您帶來重磅消息! Cerebras Systems 推出了全球最快的AI 推理服務——Cerebras Inference,該服務以其驚人的速度和極具競爭力的價格,徹底改變了AI 推理領域的遊戲規則。它在處理各種AI 模型,特別是大型語言模型(LLMs)方面表現出色,速度是傳統GPU 系統的20 倍,價格卻低至十分之一甚至百分之一。這將如何影響AI 應用的未來發展呢?讓我們一起深入了解。
性能AI 計算領域的先驅Cerebras Systems 推出了一種開創性的解決方案,該解決方案將徹底改變AI 推理。 2024年8月27日,該公司宣布推出Cerebras Inference,這是全球最快的AI 推理服務。 Cerebras Inference 的效能指標使基於GPU 的傳統系統相形見絀,以極低的成本提供20倍的速度,為AI 計算樹立了新的標竿。
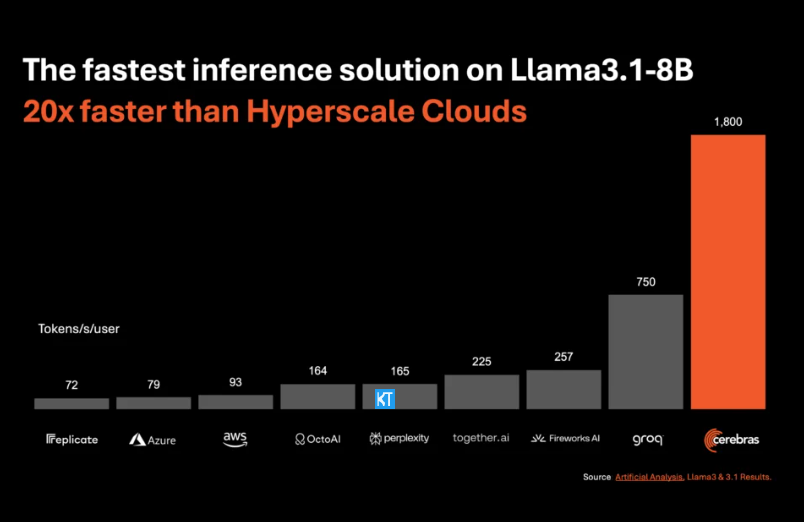
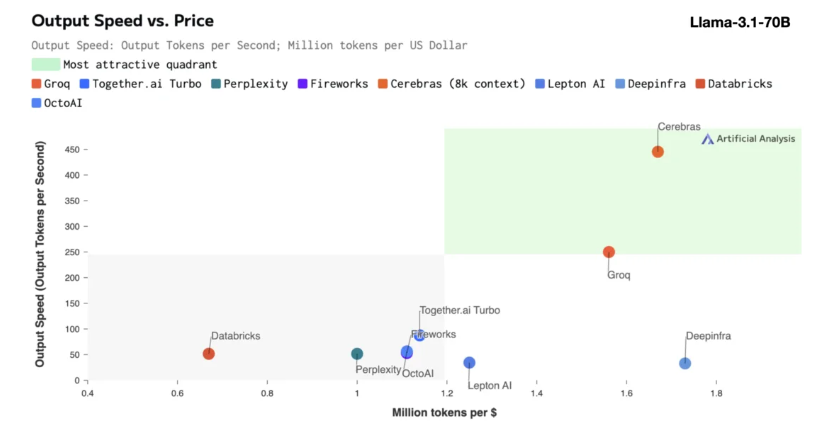
Cerebras推理特別適合處理各類AI 模型,尤其是快速發展的「大語言模型」(LLMs)。以最新的Llama3.1模型為例,其8B 版本每秒可處理1800個token,而70B 版本則為450個token。這速度不僅是NVIDIA GPU 解決方案的20倍,價格也更具競爭力。 CerebrasInference的定價起步僅為每百萬個token10美分,70B 版本則為60美分,相較於現有GPU 產品,性價比提升了100倍。
令人印象深刻的是,Cerebras Inference在保持業界領先準確度的同時,也實現了這樣的速度。與其他以速度為先的方案不同,Cerebras始終保持在16位數領域內進行推理,確保效能提升不會以犧牲AI 模型輸出品質為代價。人工分析公司的執行長米哈・希爾- 史密斯表示,Cerebras 在Meta 的Llama3.1模型上達到了超越1,800個輸出token 每秒的速度,創造了新記錄。
AI 推理是AI 計算中成長最快的部分,約佔整個AI 硬體市場的40%。高速度的AI 推理,如Cerebras 所提供的,猶如寬頻網路的出現,開啟了新的機會,為AI 應用迎來了新紀元。開發者可以藉助CerebrasInference來建構需要複雜即時效能的下一代AI 應用,如智慧代理和智慧系統。
Cerebras Inference提供了三個定價合理的服務層次:免費層、開發者層和企業層。免費層提供API 訪問,使用限制慷慨,非常適合廣泛用戶。開發者層則提供靈活的無伺服器部署選項,企業層則針對持續負載的組織提供客製化服務和支援。
在核心技術上,Cerebras Inference採用的是CerebrasCS-3系統,由業界領先的Wafer Scale Engine3(WSE-3)驅動。這個AI 處理器在規模和速度上都無與倫比,提供了比NVIDIA H100多7000倍的記憶體頻寬。
Cerebras Systems不僅在AI 計算領域中引領潮流,還在醫療、能源、政府、科學計算和金融服務等多個行業中扮演著重要角色。透過不斷推進技術創新,Cerebras正在幫助各領域的組織應對複雜的AI 挑戰。
劃重點:
Cerebras Systems服務速度提升20倍,價格更具競爭力,開啟AI 推理新紀元。
支援各類AI 模型,特別是在大語言模型(LLMs)上表現卓越。
提供三種服務層次,方便開發者和企業用戶靈活選擇。
總而言之,Cerebras Inference 的出現標誌著AI 推理領域的一個重要里程碑,其卓越的性能和經濟性將推動AI 應用的廣泛普及和創新發展,值得業界關注和期待! Downcodes小編將持續為您帶來更多科技前沿資訊。