在AI技術快速發展的今天,小型語言模型(SLM)因其在資源受限設備上的運作能力而備受關注。 Nvidia團隊近期發布了Llama-3.1-Minitron4B,這是一個基於Llama 3模型壓縮而成的優秀小型語言模型。它利用模型剪枝和蒸餾技術,在性能上與更大的模型媲美,同時具備高效的訓練和部署優勢,為AI應用帶來了新的可能性。 Downcodes小編將帶您深入了解這項技術的突破。
在現今科技公司紛紛追逐在裝置上實現人工智慧的時代,越來越多的小型語言模式(SLM)應運生,能夠在資源受限的裝置上運作。最近,Nvidia 的研究團隊利用前沿的模型剪枝和蒸餾技術,推出了Llama-3.1-Minitron4B,這是Llama3模型的壓縮版本。這個新模型在性能上不僅可以與更大的模型媲美,還能與同等規模的小型模型競爭,同時在訓練和部署上都顯得更有效率。
剪枝和蒸餾是創建更小、更有效率語言模型的兩項關鍵技術。剪枝是指去除模型中不重要的部分,包括「深度剪枝」—— 去掉整個層,和「寬度剪枝」—— 去掉特定元素如神經元和注意力頭。而模型蒸餾則是從一個大模型(即「教師模型」)轉移知識和能力到一個更小、更簡單的「學生模型」。
蒸餾主要有兩種方式,第一種是透過“SGD 訓練”,讓學生模型學習教師模型的輸入和響應,第二種是“經典知識蒸餾”,在這裡,學生模型除了學習結果外,還要學習教師模型的內部活化。
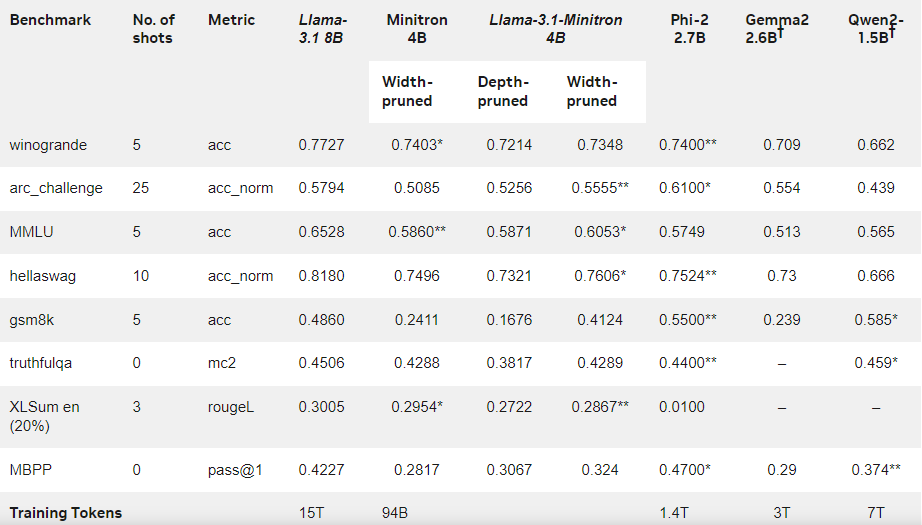
在先前的研究中,Nvidia 的研究人員成功地將Nemotron15B 模型透過剪枝和蒸餾的方式減少到一個8億參數的模型,最終又進一步精簡至4億參數。這個過程不僅在著名的MMLU 基準測試中提高了16% 的效能,而且所需的訓練資料也比從頭訓練少了40倍。
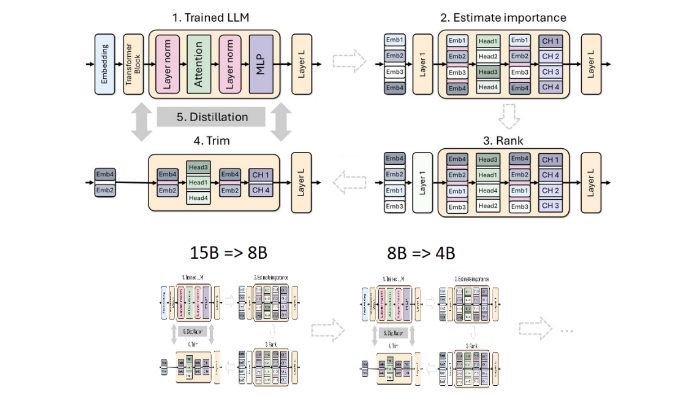
這次,Nvidia 團隊在Llama3.18B 模型的基礎上,採用相同的方法打造出4億參數的模型。首先,他們在一個包含940億個標記的資料集上對未剪枝的8B 模型進行了微調,以應對訓練資料和蒸餾資料集之間的分佈差異。接著,採用了深度剪枝和寬度剪枝兩種方式,最後得到了Llama-3.1-Minitron4B 的兩個不同版本。
研究人員透過NeMo-Aligner 對剪枝後的模型進行了微調,並評估其在指令跟隨、角色扮演、檢索增強生成(RAG)和函數呼叫等方面的能力。
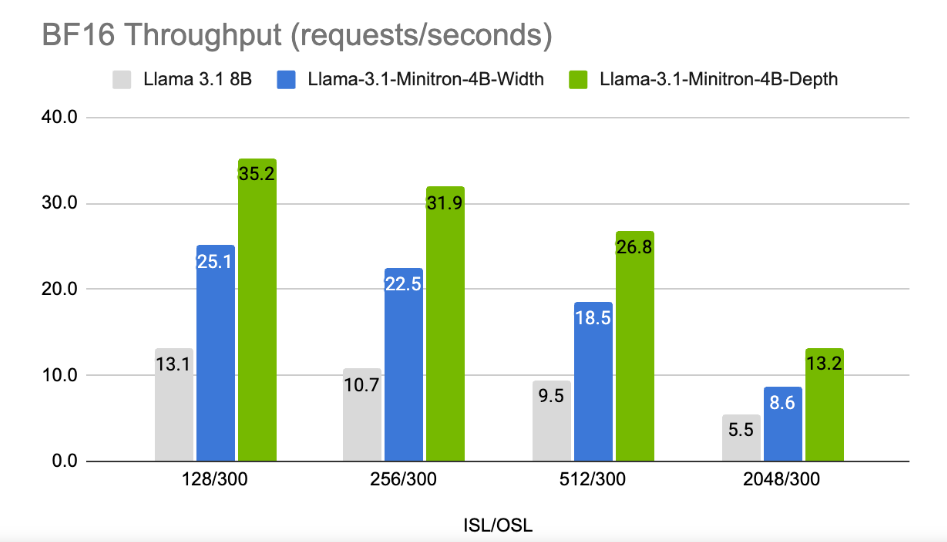
結果顯示,儘管訓練資料量較小,Llama-3.1-Minitron4B 的性能仍接近其他小型模型,表現出色。該車型的寬度剪枝版本已在Hugging Face 上發布,允許商業使用,幫助更多用戶和開發者受益於其高效和卓越的表現。
官方部落格:https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
劃重點:
Llama-3.1-Minitron4B 是Nvidia 基於剪枝和蒸餾技術推出的小型語言模型,具有高效的訓練和部署能力。
此模型在訓練過程中使用的標記量比從頭訓練減少了40倍,表現卻有明顯提升。
? 寬度剪枝版本已在Hugging Face 發布,方便用戶進行商業使用和開發。
總而言之,Llama-3.1-Minitron4B 的出現標誌著小型語言模型發展的新里程碑,其高效的性能和便捷的部署方式,將為更多開發者和用戶帶來福音,加速AI技術的普及和應用。 Downcodes小編期待未來更多類似的創新成果出現。