蘋果近日發布了名為Matryoshka Diffusion Models(MDM)的全新圖像和視頻生成方法,這項突破性技術被形像地稱為“套娃擴散模型”,其核心在於將小的結構嵌套在大的結構之中,如同俄羅斯娃娃般層層遞進。 Downcodes小編將帶你深入了解這項技術的創新之處,以及它對AI影像生成領域的革命性影響。
近日,科技巨頭蘋果公司再次展現了其強大的技術創新能力,推出了一種名為Matryoshka Diffusion Models(MDM)的全新圖像和視頻生成方法,這一突破性技術被形像地稱為套娃擴散模型。
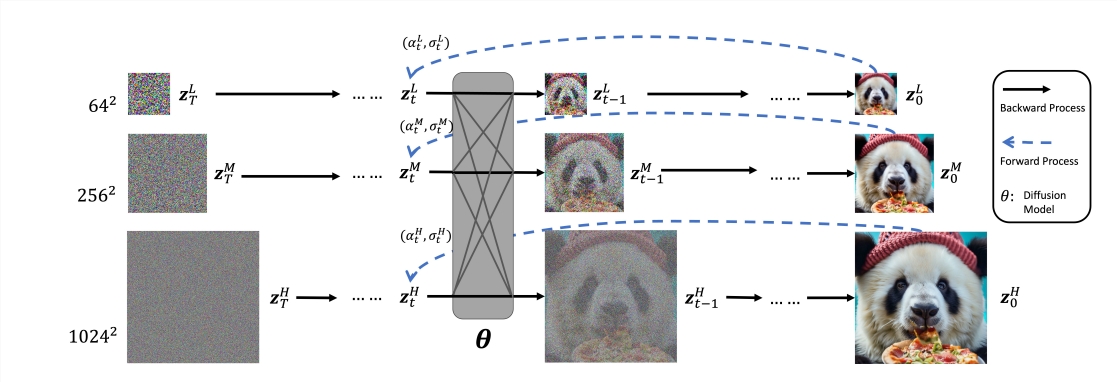
MDM的名字源自俄羅斯娃娃,這個巧妙的命名不僅充滿趣味性,更體現了其核心技術理念──將小小的結構嵌套在大的結構中。就像每個娃娃裡都藏著一個更小但同樣精緻的套娃一樣,MDM能夠在不同解析度下同時處理影像,實現從低清晰度草圖到高清晰度細節的無縫生成。

這種創新方法的魅力在於它能同時駕馭多個解析度的影像處理。想像一下,就好像有一群技藝精湛的畫家,每個人專注於畫布的不同區域,卻又能默契配合,共同創作出一幅精美絕倫的藝術品。 MDM透過在多個解析度上進行聯合去噪的技術,使得產生的影像細節更加豐富,更具真實感,大大提升了影像的整體品質。
MDM的核心架構稱為NestedUNet,這項設計理念進一步強化了娃娃的概念。在這個架構中,每一層級都包含了一個更小但功能完整的子結構,就像娃娃中的每一個都是獨立完整的。這種獨特的設計使得MDM在處理小規模輸入時,能夠充分利用高層次的特徵和參數,從而實現更有效率的學習和生成過程。

目前,高品質影像和視訊生成模型普遍面臨巨大的計算和最佳化挑戰。傳統方法要麼在像素層級上逐步生成,要麼先訓練一個壓縮影像模型,然後在低解析度影像上處理。而MDM的訓練過程更像是循序漸進地教導一個孩子學習走路,從蹣跚學步到健步如飛。它採用了一種漸進式訓練方法,從低分辨率開始,逐步過渡到高分辨率,這種方法讓模型在面對新的高分辨率圖像時表現得更加穩定和高效。
蘋果公司的研究團隊通過一系列基準測試,充分展現了MDM的強大實力。無論是在類條件圖像生成,還是文字到圖像、文字到視訊的轉換應用中,MDM都表現出了卓越的性能。特別值得一提的是,即使在僅有1,200萬像素的CC12M資料集上訓練,MDM也展現了驚人的零樣本泛化能力,這意味著它能夠在沒有見過的場景中表現出色。
研究結果顯示,MDM能夠產生高達1024x1024像素解析度的影像,即使在相對有限的資料條件下,它也能出色地完成任務,產生符合要求的高品質影像。這項特性大大拓展了AI影像生成技術的應用範圍,為創意產業、設計產業等領域帶來了新的可能性。
儘管MDM在影像和視訊生成領域已經取得了令人矚目的成就,但這可能只是冰山一角。未來的MDM有望變得更加智能,能夠理解更複雜的上下文訊息,產生更真實、更多樣化的內容。我們可以期待,這項技術將在虛擬實境、擴增實境、電影製作、遊戲開發等多個領域中發揮重要作用。
蘋果公司推出的這套娃娃擴散模型技術,無疑為AI影像生成領域帶來了一股清新的技術風潮。它不僅提高了影像生成的效率和質量,也為整個產業的發展指明了新的方向。隨著科技的不斷改進和應用的深入,我們有理由相信,MDM將在未來的數位創意世界中扮演越來越重要的角色,為我們帶來更多令人驚嘆的視覺體驗。
專案頁:https://top.aibase.com/tool/ml-mdm
論文:https://arxiv.org/pdf/2310.15111
總而言之,蘋果的Matryoshka Diffusion Models展現了AI影像生成技術的巨大潛力,其高效、高品質的影像生成能力以及出色的零樣本泛化能力,為未來數位創意產業的發展帶來了無限可能。 讓我們拭目以待,看看這項技術將如何進一步革新我們的視覺體驗。